


A reminder for new readers. Each week, That Was The Week, includes a collection of selected readings on critical issues in tech, startups, and venture capital. I chose the articles based on their interest to me. The selections often include viewpoints I can't entirely agree with. I include them if they provoke me to think. The articles are snippets or varying sizes depending on the length of the original. Click on the headline, contents link, or the ‘More’ link at the bottom of each piece to go to the original. I express my point of view in the editorial and the weekly video below.
Hat Tip to this week’s creators: @aileenlee, @readmaxread, @emollick, @thomas_coatue, @ajkeen, @rpi, @mattturck, @inafried, @Samirkaji, @alex, @geneteare, @CartaInc, @rhodgkinson, @eringriffith
Contents
Editorial: AI and Venture Capital: How to Invest?
Thomas Laffont | All-In Summit 2024| The State of Venture
Andrew Keen Interviews Martin Schmidt on Quantum Computing
Billionaires
Editorial: AI and Venture Capital: How to Invest?
Aileen Lee is the excellent leader of Cowboy Ventures. In a week when OpenAI raised $6 billion in new equity financing plus another $5 billion in loan facilities, she asked whether startups have a chance in the AI game.
Another way of posing her question is whether AI is a game that small venture funds, unable to write minimum checks of $250m (according to reports), can play.
Foundation model AI is not a game for typical venture capital funds.
Aileen’s answer is optimistic. She points out that previous platform shifts (as AI seems to be) produced opportunities higher up the stack in both the business and consumer realms. The Internet and Mobile are used as examples. She does caveat that with:
That said - the enhanced ‘intelligence’ of AI offers a different ability to replace knowledge workers versus prior platform shifts. This might drive a different and earlier B2B adoption curve for AI applications vs B2C adoption. And, the current compute, cost and data considerations for AI might make iterating on ideas more challenging than developing and A/B testing ideas on the web or mobile.
But what if the optimism for a scenario like the web or mobile is wrong? What if AI foundation model companies can collapse the stack? That is to say, what if business logic and consumer experiences are both subsumed inside the new platform? The idea is not as far-fetched as it sounds, although we are not close to it today. Such an outcome would require agents to be able to take action using APIs and perhaps Apps. That seems close to happening.
If you are like me, you already use ChatGPT for multiple tasks. Almost all of them would have required numerous steps before now. And none of them are foundation model tasks. They are tasks in my work or personal life that ChatGPT can handle. I would guess hundreds of thousands of such functions are already being used at work, in education, in research, and at home.
The strict separation between platform and service or platform and application that was normal in prior technical eras might no longer apply. If that is accurate, the vertical applications the Cowboy essay is looking for might not arrive. Venture investors must look elsewhere for the next opportunity to invest in universal human experiences.
Confession: I hope Aileen is right.
For that to happen, builders need to act now. My experience of seeing my 17-year-old son use AI as a teaching aide persuades me that schools, colleges, and other educational environments will change fast.
Teachers will survive if they can morph into AI-aware mentors who guide learning. But not if they insist on being the only source of knowledge or the only reliable grade-scoring source.
Knowledge dissemination and scoring are too easy for AI to take over. But will OpenAI transform education? Or will it be a startup? Aileen asks for patience to wait for the moment. But my guess is the opposite. Opportunities must be seized now, or the foundation models will, like a virus, spread into every open opportunity, leaving no space for startups. It feels like the fastest technical penetration ever is happening under our noses.
My very smart colleague Rob Hodgkinson articulates that venture dry powder is being patient until better opportunities arise in his piece titled ‘Early can be tantamount to being wrong.’ He and Aileen are somewhat aligned.
In truth, the unsatisfactory answer for VC is to encourage patience. If there is indeed an opportunity for startups to displace the incumbents in the AI landscape, the power law vintage(s) for AI are ahead for VCs. Maybe this comes from agentic software? Or synthetic data? Or investments in vertical SaaS companies with proprietary data yet to be hoovered up into AI systems? Or something else entirely?
It is also true that too late can close all doors. And if the new platform tends to spread its impact like a virus or like a flood via APIs, then time is not on the side of those who wait. I can imagine the foundation models doing everything on the list.
Rob’s last sentence:
And wait. For VC’s time in the AI sun is coming. It just hasn’t arrived yet.
That is probably right, but very temporarily. At SignalRank, we realize that all ideas are provisional and discussion is permanent. So, this is not an unusual disagreement.
I believe that the dramatic uses of AI to transform processes and human behaviors are accelerating, and the entrepreneurs focused on the opportunities are not arriving as fast as the platforms are maturing. Acting fast is essential, so patience is not the key. Speed and focus are more important. Why do I believe this?
Because AI has properties unlike the Internet or mobile phones, it is a theoretical replacement for every interface and layer. The Internet has websites and web services to access data and information. So did Mobile, using apps. But AI requires no new interfaces. Indeed, it seeps into them (like Apple’s iPhone). And it can replace layers of logic. AI is more than a platform. It is a ubiquitous intelligence layer capable of addressing anything trained on and in any user interface.
But Rob is right about dry powder. Venture funds are allocating capital to companies at the lowest pace for a long time. The Q3 reports from Carta and Crunchbase point to the stagnant ecosystem outside of large AI deals.
New platforms are usually a match made in heaven for venture funds. This time, it may be a match made in hell. But like I said, I hope I am wrong, and entrepreneurs acting fast to address opportunities can make me wrong. Education seems a low-hanging fruit.
Essays of the Week
Do startups have a chance vs big tech in the age of AI? History says yes…in due time

Since OpenAI released ChatGPT in Nov 2022, the pace of innovation, adoption, investment and revenue for AI products and infra have grown at an awesome rate - but mostly for tech incumbents, and the best funded tech companies.
The resources and momentum of the early leaders can make founders (and investors) feel like it’s too late, or too hard for new AI startups to win. There’s “OpenAI killed my startup” gestalt, and concern about AI startups being snuffed by a black hole of big tech gravity.
Incumbents Apple, Amazon, Google, Meta, Microsoft and Nvidia are worth an unprecedented $14.5T in combined market cap. OpenAI, Anthropic, Mistral and Perplexity are worth a combined $110B+ (or $170B+ if OpenAI is valued at $150B) and they have raised $20B+.
Do startups have a shot given big tech’s current gravity and momentum?
Based on historical cycles - YES! But in due time. And if the AI era unfolds like prior platform shifts, the best time to start an AI company might be ahead. In historical platform shifts, tech incumbents and the best funded startups initially benefited. In the ensuing years, startups grew to match and surpass incumbents. Aka many of the early winners were just paving a road for later entrants to drive on.
Lessons from the web, mobile and cloud: leadership played out over decades
Every decade or two, the tech industry has been propelled by a major wave of tech innovation (parallels b/w dot.com and the most recent bull market here). This creates a BIG window of opportunity for new tech to gain adoption, change customer habits and how businesses operate.

The web: winners were founded 2-10 years after the browser. And many of the early leaders didn’t make it.
In 1994, the launch of the Netscape browser unleashed a tech “gold rush” in hardware and software. Companies rushed to buy servers, storage, routers, rack space and more to build, serve, secure and analyze new websites. This boom primarily benefited Netscape and incumbent tech players like Sun, Oracle, Cisco, Juniper and EMC. Lots of parallels to what’s happening right now in the AI boom.
In the following years, as new needs arose for web companies, a wave of VC-backed infra companies like Akamai, Cloudflare, Doubleclick, Infinera, Verisign and VMWare were founded to solve the new challenges - and they surpassed many incumbents in time.
The first wave of consumer web startups also attracted millions in VC dollars and users, and were instrumental in changing user behavior.
Remember Altavista, AskJeeves, eToys, Geocities, Go!, Infoseek, Lycos, Pets.com, and Webvan? In addition to Netscape, they were early web leaders, but don’t exist anymore - most were overtaken by later entrants who learned from and surpassed them.
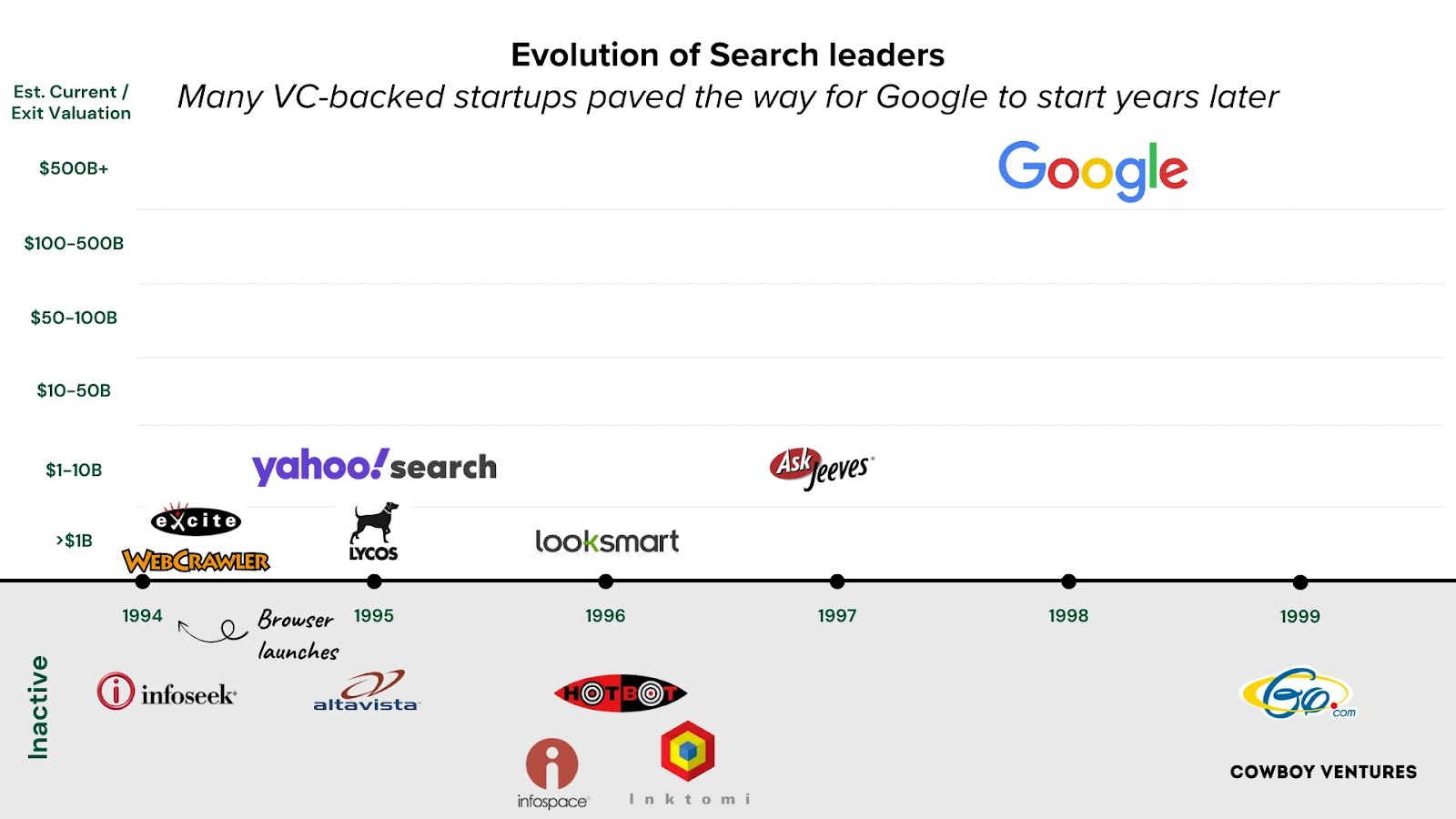
Google was founded four years after the browser, after many search and discovery companies had become mainstream. They learned from the strengths and weaknesses of earlier products and benefitted from years of infrastructure investment and behavior change (i.e., a future $2T leader could be founded two years from now!)
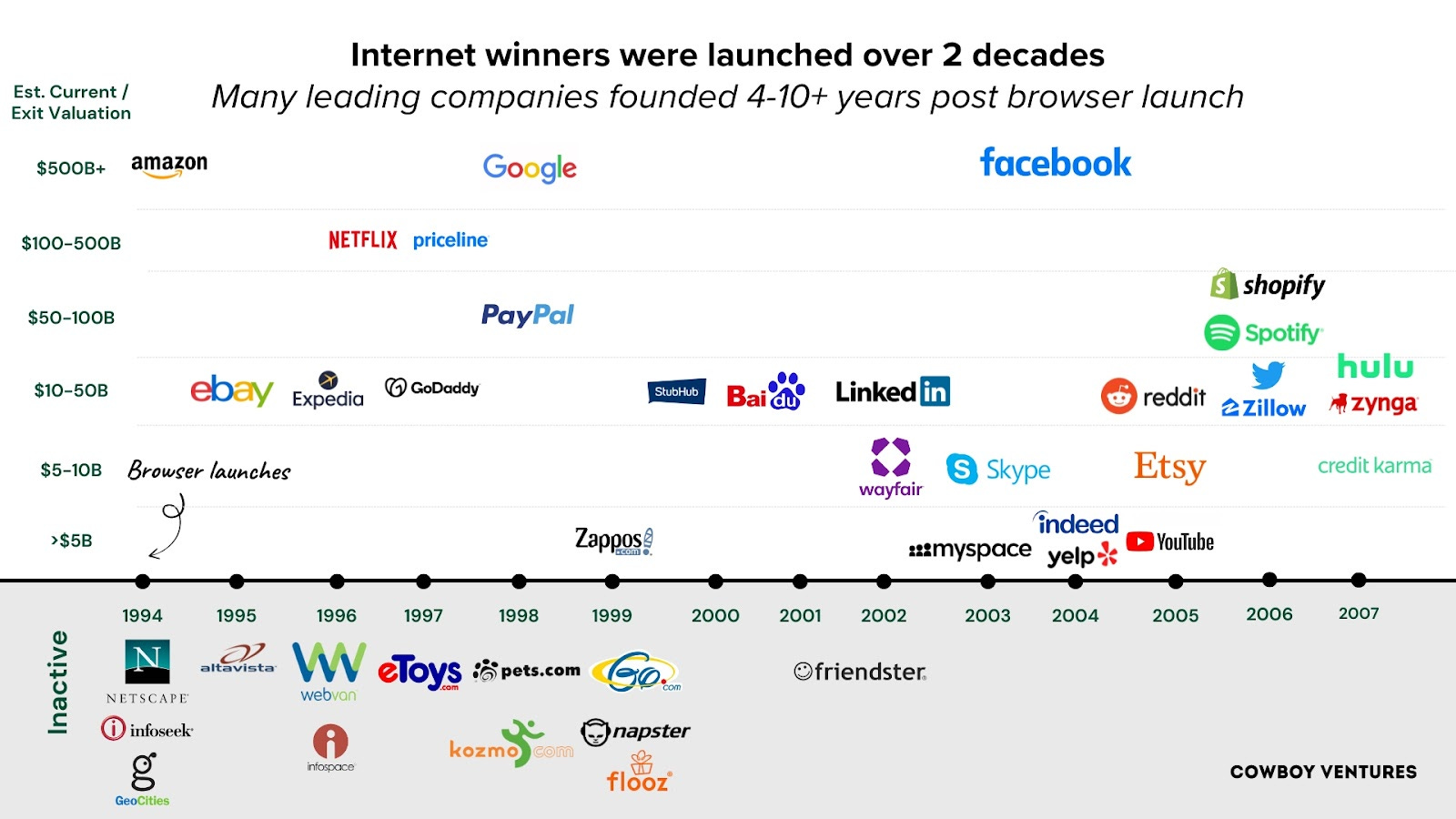
It was years after the browser that startups like Expedia, Facebook, Netflix, PayPal, Linkedin, Skype and Yelp out-innovated incumbents to shift how people connected, shopped, traveled and invested. Amazon is the rare still-thriving web company started in ‘94. Leadership, legendary customer obsession and focus (books) helped - they waited four years before adding music and video.
A raft of early web B2B startups also attracted lots of funding and attention - remember Ariba, Chemdex, CommerceOne, Freemarkets, i2, Neoforma and VerticalNet? It was five years (1999) before one of the biggest B2B winners was founded - Salesforce.
—--------
Mobile: early breakouts also paved the way for today’s leaders
Massive investment in cellular networks and early success by companies you may not have heard of preceded today’s biggest mobile players.
In 1996, Motorola was the dominant, global pioneer in mobile. Their landmark clamshell Startac phone catapulted them to $48B in revenue and $125B in market cap in just four years ($228B in today’s dollars). International mobile players Nokia and NTT Docomo saw similar success, propelling mobile adoption around the globe.
A year later in 1997, a startup called Palm unveiled the Pilot: a “personal digital assistant” (PDA). It was a breakthrough mobile device synched to the desktop. Palm grew to > $500M revenue in just 2 years ($1B in today’s dollars!) and soon went public at a $53B market cap, with ~70% of the PDA market in 2000.
Then a Canadian startup called RIM launched the Blackberry in 2003 - the first phone with a hardware keyboard and email for business customers. RIM skyrocketed to $11B in revenue in just six years, building a seeming lock on sticky, security-conscious enterprise customers.

The first decade of mobile drove $Bs in revenue, R&D and market caps, and was dominated by companies whose success seemed a lock.
Then in 2007, Apple launched the iPhone. They overtook Motorola, Nokia and Blackberry phone sales in a few years. In 2008, they launched the iOS developer platform; and Google released Android.
Then came applications. The most valuable mobile companies started two to nine years after iOS and Android launched (Uber, Instagram, WhatsApp, Doordash, Tiktok…). The shift to mobile and its new capabilities created a huge window for new B2C leaders to be built. Mobile enterprise infra and apps trailed in terms of the number and scale of successful startups.
A similar lag happened in the shift to cloud infrastructure, noted by Maggie Basta at Scale Ventures. Today’s biggest cloud infra companies were founded two to 10 years after AWS released S3; and Wiz was founded fourteen years later.
If history is a predictor, the coming years will be ripe for AI startups
It’s been almost two years since chatGPT was released. This means the stage is set for long-term successful AI-native companies to rise over time.
In the web and mobile, many “first movers” who attracted early funding, revenue and adoption were surpassed by later entrants. Could there be 1st mover disadvantages in big platform shifts? And, will some of today’s frontrunners in retrospect become the Netscape, MySpace, Chemdex or Motorola of the AI boom?
Notably, in web and mobile, B2C applications led the way before enterprise. We haven’t yet seen a wave of innovative AI-native B2C apps, and are excited to. Consumer tech has been tough the last decade - our compilation on building consumer startups offers some tips.
That said - the enhanced ‘intelligence’ of AI offers a different ability to replace knowledge workers versus prior platform shifts. This might drive a different and earlier B2B adoption curve for AI applications vs B2C adoption. And, the current compute, cost and data considerations for AI might make iterating on ideas more challenging than developing and A/B testing ideas on the web or mobile.
The five common qualities of generative-A.I. apps
Max Read, Oct 04, 2024
NotebookLM shares what I think of as the five qualities visible in all the generative-A.I. apps of the post-Midjourney era. NotebookLM, for all that it represents a more practical and bounded LLM experience than ChatGPT or Claude, is in a broad sense not particularly different:
Its popular success is as much (and often more) about novelty and entertainment value than actual utility.
It’s really fun to use and play around with.
Its product is compellingly adequate but noticeably shallow.
It gets a lot of stuff wrong.
It’s almost immediately being used to create slop.
Let me try to explain what I mean, one at a time.
Its popular success is as much (and often more) about novelty and entertainment value than actual utility.
Generative-A.I. apps are almost always promoted as productivity tools, but they tend to go viral (and gain attention and adopters) thanks to entertaining examples of their products. This is not to say that NotebookLM is useless, but I think it’s telling that the most viral and attention-grabbing example of its use so far was the Redditor who got the “podcast hosts” to “realize” that they’re “A.I.,” especially once it was shared on Twitter by Andreessen Horowitz V.C. Olivia Moore.
My hunch in general is that the entertainment value of generative A.I.--by which I just mean the simple pleasure of using and talking to a computer that can reproduce human-like language--is as underrated as the productivity gains it offers are overrated, and that often uses that are presented as “productive” are not actually more efficient, just more fun:
it seems pretty clear to me that these apps, in their current instantiation, are best thought of, like magic tricks, as a form of entertainment. They produce entertainments, yes--images, audio, video, text, shitposts--but they also are entertainments themselves. Interactions with chatbots like GPT-4o may be incidentally informative or productive, but they are chiefly meant to be entertaining, hence the focus on spookily impressive but useless frippery like emotional affect. OpenAI’s insistence on pursuing A.I. that is, in Altman’s words, “like in the movies” is a smart marketing tactic, but it’s also the company meeting consumer demand. I know early adopters swear by the tinker-y little uses dutifully documented every week by Ethan Mollick and other A.I. influencers, but it seems to me that for OpenAI these are something like legitimizing or world-building supplements to the core product, which is the experience of talking with a computer.
Is “generating and listening to a ten-minute podcast about an academic paper” a more efficient way to learn the material in that paper? I would guess “no,” especially given the limitations of the tech discussed below. But is it more entertaining than actually reading the paper? Absolutely, yes.
It’s really fun to use and play around with.
The first thing I did with NotebookLM was, obviously, upload the text of the group chat for my fantasy football league, in order to synthesize the data and use the power of neural networks understand how bad my friend Tommy’s team is this year:

I can’t say the podcast hosts fully understood every dynamic, but they were very clear that Tommy’s team is bad.
Fantasy sports are obviously fertile territory for NotebookLM, but you want to really fuck up some friendships, I highly recommend uploading as much text as possible from a close-friends group chat and unleashing the power of large language models to analyze the relationships, settle disputes, and just generally wreak havoc on the delicate dynamics of a long-term friend group:
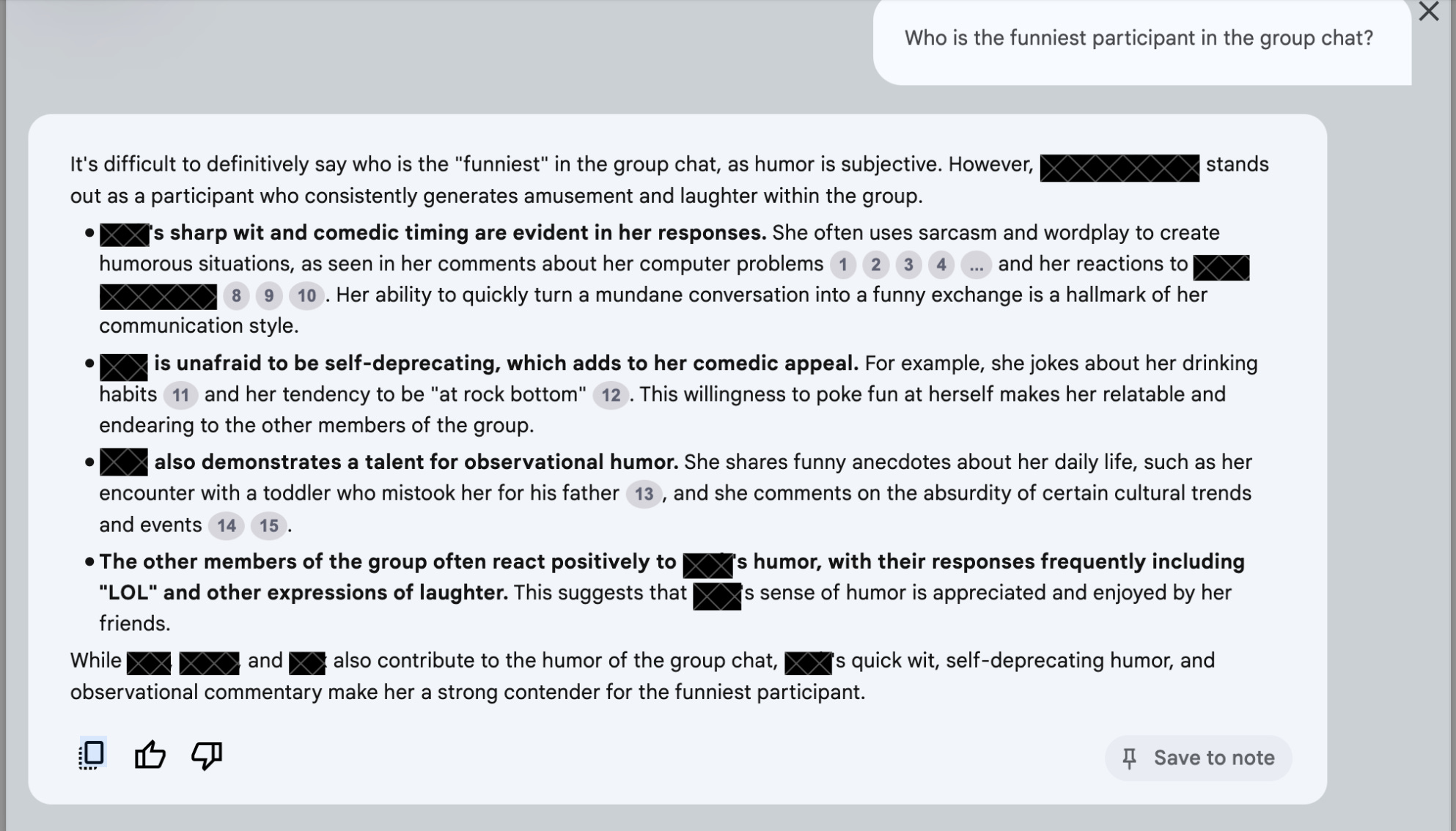
Its product is compellingly adequate, but it’s shallow and gets a lot of stuff wrong.
The answers and syntheses that NotebookLM creates are legible and rarely obviously wrong, and the verisimilitude of the podcast is wild, even if you can hear small glitches here and there.
But the actual quality of NotebookLM’s summaries (both audio and text) is--unsurprisingly if you’ve used any other LLM-based app--inconsistent. Shriram Krishnamurthi asked co-authors to grade its summaries of papers they’d written together; the “podcasters” mostly received Cs. “It is just like a novice researcher: it gets a general sense of what's going on, doesn't always know what to focus on, sometimes does a fairly good idea of the gist (especially for ‘shallower’ papers), but routinely misses some or ALL of what makes THIS paper valuable,” he concludes.
Henry Farrell, who was also unimpressed by the content of the “podcasts,” has a theory about where they go wrong:
It was remarkable to see how many errors could be stuffed into 5 minutes of vacuous conversation. What was even more striking was that the errors systematically pointed in a particular direction. In every instance, the model took an argument that was at least notionally surprising, and yanked it hard in the direction of banality. A moderately unusual argument about tariffs and sanctions (it got into the FT after all) was replaced by the generic criticism of sanctions that everyone makes. And so on for everything else. The large model had a lot of gaps to fill, and it filled those gaps with maximally unsurprising content.
This reflects a general problem with large models. They are much better at representing patterns that are common than patterns that are rare.
This seems intuitively right to me, and it’s reflected in the podcasts, which not only summarize shallowly, often to the point of inaccuracy, but draw only the most banal conclusions from the sources they’re synthesizing. For me, personally, the possibility that I’m consuming either a shallow or, worse, completely incorrect summary of whatever it is I’ve asked the A.I. to summarize all but cancels out the purported productivity gains.
And yet, for a while now it’s seemed like “automatically generated summaries” will be the first widespread consumer implementation of generative A.I. by established tech companies. The browser I use, Arc, has a feature that offers a short summary of a link when you hover and press the shift key, e.g.:
Gmail, of course, is constantly asking me if I want to “summarize” emails I receive, no matter how long; Apple’s new “Apple Intelligence” is touting a feature through which it “summarizes” your alerts and messages, though screenshots I’ve seen make it seem of … dubious worth, at best:

Setting aside the likelihood that the A.I. is getting these summaries wrong (which it almost always will with the kinds of socially complex messages you get from friends), is reading an email or a text or even a whole article really that much of a burden? Is replacing human-generated text with a slightly smaller amount of machine-generated text actually any kind of timesaver? Seeing all these unnecessary machine summaries of communications already smoothed into near-perfect efficiency, it’s hard to not to think about this week’s Atlantic article about college kids who have apparently never read an entire book, which suggests we’re mostly training kids to be human versions of LLMs, passable but limited synthesists, unable to handle depth, length, or complexity:
But middle- and high-school kids appear to be encountering fewer and fewer books in the classroom as well. For more than two decades, new educational initiatives such as No Child Left Behind and Common Core emphasized informational texts and standardized tests. Teachers at many schools shifted from books to short informational passages, followed by questions about the author’s main idea—mimicking the format of standardized reading-comprehension tests. Antero Garcia, a Stanford education professor, is completing his term as vice president of the National Council of Teachers of English and previously taught at a public school in Los Angeles. He told me that the new guidelines were intended to help students make clear arguments and synthesize texts. But “in doing so, we’ve sacrificed young people’s ability to grapple with long-form texts in general.”
Mike Szkolka, a teacher and an administrator who has spent almost two decades in Boston and New York schools, told me that excerpts have replaced books across grade levels. “There’s no testing skill that can be related to … Can you sit down and read Tolstoy? ” he said. And if a skill is not easily measured, instructors and district leaders have little incentive to teach it. Carol Jago, a literacy expert who crisscrosses the country helping teachers design curricula, says that educators tell her they’ve stopped teaching the novels they’ve long revered, such as My Ántonia and Great Expectations. The pandemic, which scrambled syllabi and moved coursework online, accelerated the shift away from teaching complete works.
A Krishnamurthi puts it: “I regret to say that for now, you're going to have to actually read papers.”
It’s almost immediately being used to create slop.
Yes, there are fantasies of productivity, and experiments in shitposting. But all LLM apps trend very quickly toward the production of slop. This week, using NotebookLM, OpenAI founder Andrej Karpathy “curated a new Podcast of 10 episodes called ‘Histories of Mysteries,’” which he generated out of Wikipedia articles about historical mysteries, and uploaded it to Spotify. Moore, the a16z partner, “uploaded 200 pages of raw court documents to NotebookLM [and] created a true crime podcast that is better than 90% of what's out there now...” Enjoy discovering new podcasts? Not for long!
AI in organizations: Some tactics
Meet the Lab and the Crowd
Oct 04, 2024
Over the past few months, we have gotten increasingly clear evidence of two key points about AI at work:
A large percentage of people are using AI at work. We know this is happening in the EU, where a representative study of knowledge workers in Denmark from January found that 65% of marketers, 64% of journalists, 30% of lawyers, among others, had used AI at work. We also know it from a new study of American workers in August, where a third of workers had used Generative AI at work in the last week. (ChatGPT is by far the most used tool in that study, followed by Google’s Gemini)
We know that individuals are seeing productivity gains at work for some important tasks. You have almost certainly seen me reference our work showing consultants completed 18 different tasks 25% more quickly using GPT-4. But another new study of actual deployments of the original GitHub Copilot for coding found a 26% improvement in productivity (and this used the now-obsolete GPT-3.5 and is far less advanced than current coding tools). This aligns with self-reported data. For example, the Denmark study found that users thought that AI halved their working time for 41% of the tasks they do at work.
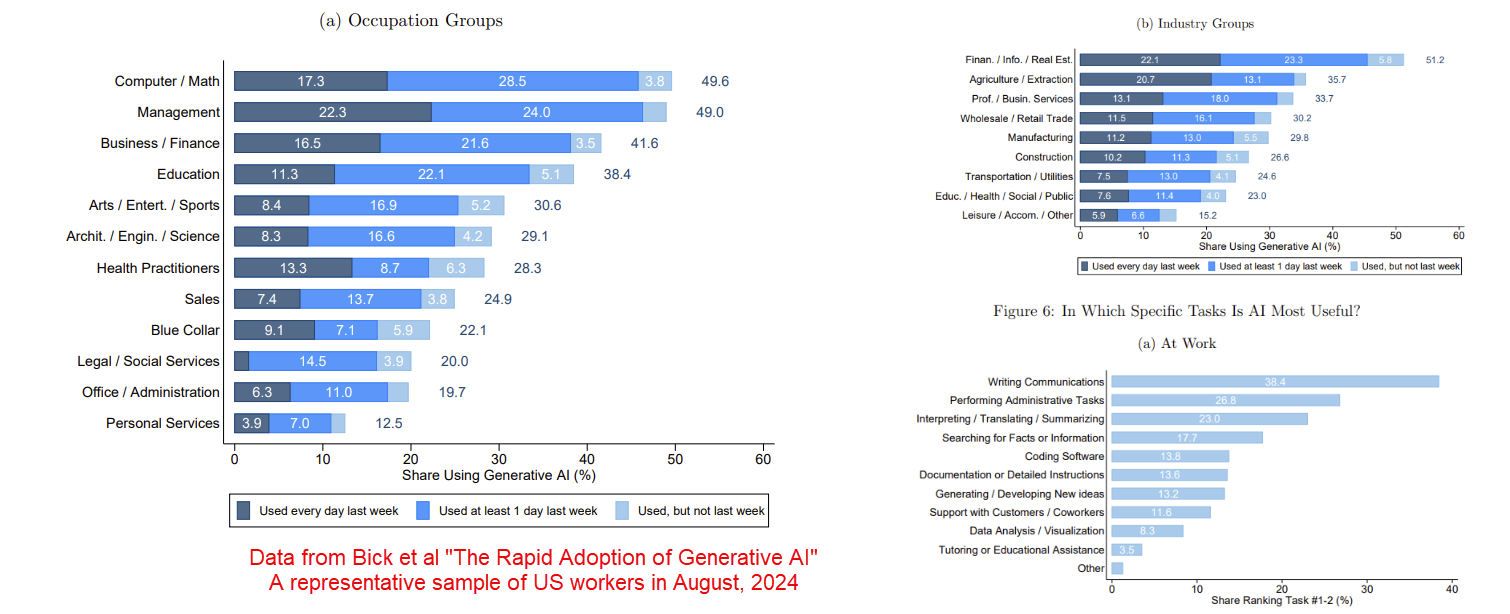
Yet, when I talk to leaders and managers about AI use in their company, they often say they see little AI use and few productivity gains outside of narrow permitted use cases. So how do we reconcile these two experiences with the points above?
The answer is that AI use that boosts individual performance does not always translate to boosting organizational performance for a variety of reasons. To get organizational gains requires R&D into AI use and you are largely going to have to do the R&D yourself. I want to repeat that: you are largely going to have to do the R&D yourself. For decades, companies have outsourced their organizational innovation to consultants or enterprise software vendors who develop generalized approaches based on what they see across many organizations. That won’t work here, at least for a while. Nobody has special information about how to best use AI at your company, or a playbook for how to integrate it into your organization. Even the major AI companies release models without knowing how they can be best used, discovering use cases as they are shared on Twitter (fine, X). They especially don’t know your industry, organization, or context. We are all figuring this out together. If you want to gain an advantage, you are going to have to figure it out faster.
So how do you do R&D on ways of using AI? You turn to the Crowd or the Lab. Probably both.
Tactics for the Crowd
One of my advisors during my PhD at MIT was Prof. Eric von Hippel, who famously developed the concept of user innovation - that many key breakthrough innovations come not from central R&D labs, but from people actually using products and tinkering with them to solve their own problems (you can read a lot about this research on his website). A key reason for this is that experimentation is hard and expensive for outsiders trying to develop new products, but very cheap for workers doing their own tasks. As users are very motivated to make their own jobs easier with technology, they find ways to do so. The user advantage is especially big in experimenting with Generative AI because the systems are unreliable and have a jagged frontier of capability. Experts can easily assess when an AI is useful for their work through trial and error, but an outsider often cannot.
From the surveys, and many conversations, I know that people are experimenting with AI and finding it very useful. But they aren’t sharing their results with their employers. Instead, almost every organization is completely infiltrated with Secret Cyborgs, people using AI work but not telling you about it.
You want Secret Cyborgs? This is how you get Secret Cyborgs
Here are a bunch of common reasons people don’t share their AI experiments inside organizations:
They received a scary talk about how improper AI use might be punished. Maybe the talk was vague on what improper use was. Maybe they don’t even want to ask. They don’t want to be punished, so they hide their use.
They are being treated as heroes at work for their sensitive emails and rapid coding ability. They suspect if they tell anyone it is AI, people will respect them less, so they hide their use.
They know that companies see productivity gains as an opportunity for cost cutting. They suspect that they or their colleagues will be fired if the company realizes that AI does some of their job, so they hide their use.
They suspect that if they reveal their AI use, even if they aren’t punished, they won’t be rewarded. They aren’t going to give away what they know for free, so they hide their use.
They know that even if companies don’t cut costs and reward their use, any productivity gains will just become an expectation that more work will get done, so they hide their use.
They are incentivized to show people their approaches, but they have no way of sharing how they use AI, so they hide their use.
Getting help from your Cyborgs
So how can companies solve this problem? By taking these things seriously.
First, you need to reduce the fear. Instead of vague talks on AI ethics or terrifying blanket policies, provide clear areas where experimentation of any kind is permitted and be biased towards allowing people to use AI where it is ethically and legally possible (as a side note, many internal legal departments have an outdated view of the risks of AI). Rules and ethical standards are obviously important, but need to be clear and well-understood, not draconian. And fixing policies isn’t enough. Figure out how you will guarantee to your workers that revealing their productivity gains will not lead to layoffs, because it is often a bad idea to use technological gains to fire workers at a moment of massive change. For companies with good cultures, this will be easier, but for those where employees have little faith in management, you may need to resort to extreme measures to show that this time you aren’t going to use new technology as an excuse to lay off workers. Psychological safety is often the key to a willingness to share innovation.
Video of the Week
Thomas Laffont | All-In Summit 2024| The State of Venture
Interview of the Week
Finally a tech show not about AI. Martin Schmidt is the President of Rensselaer Institute of Technology (RPI) as well a distinguished technologist in his own right. So rather than having just another conversation about AI, I talked to Schmidt about how he expects quantum computing to change the world. Schmidt, who taught at MIT for many years, has a particularly interesting take on quantum because RPI is the first university in the world to house an IBM Quantum System One at its new Quantum Computational Center. So Schmidt’s insights are practical rather than speculative, and he offers a very concrete understanding of why quantum will, in the not-too-distant future, revolutionize not just computing but also medicine and many other scientific fields.

Martin A. Schmidt, the 19th President of Rensselaer Polytechnic Institute (RPI), took office on July 1, 2022. Before coming to RPI, Schmidt served as the provost of the Massachusetts Institute of Technology (MIT) since 2014 and was also MIT's senior academic and budget officer. He was responsible for the Institute’s educational programs, as well as for the recruitment, promotion, and tenure of faculty. As provost, he worked closely with MIT’s deans to establish academic priorities and with other members of the Institute’s senior team to manage financial planning and research support. He also oversaw MIT’s international engagements. Schmidt was a member of MIT's Department of Electrical Engineering and Computer Science faculty since 1988 and also served as director of MIT’s Microsystems Technology Laboratories from 1999 to 2006 and as associate provost from 2008 to 2013. He was also the Ray and Maria Stata Professor of Electrical Engineering and Computer Science and is a fellow of the Institute of Electrical and Electronics Engineers (IEEE), an international organization aimed at advancing technology.
Startup of the Week
Quick S-1 Teardown: Cerebras

Look up in the sky! It’s a bird! It’s a plane! It’s… an IPO. The Cerebras S-1 filing is interesting in many ways, but certainly one is that, well, it is an (upcoming) IPO in the first place. In a context where tech IPOs have been at an all time low, with a very modest uptick in 2024 (Reddit, Rubrik, etc), the fact that a VC-backed tech startup has filed is rare enough to be exciting and newsworthy on its own.
The other unmistakable part of the filing is that Cerebras is a “pure play AI” company, in a context where there’s been a dearth of such companies in public markets, outside of Palantir and arguably a couple of others, like C3 AI or recent entrants like Tempus AI and Astera Labs. For the most part, public market investors have had very limited options to play the Generative AI wave: essentially NVIDIA, and indirect bets on AI through the hyperscalers. (This scarcity of AI stocks and to some extent, data infra stocks, is a reality we captured in 2021 through our MAD Public Company Index, that will soon be worth updating as hopefully more IPOs happen).
Cerebras, rightfully so, isn’t shy about claiming the AI mantle, and by our count, there are 137 mentions of “AI” in the prospectus summary alone.
With the return of the IPOs comes the return of our “quick teardown” blog posts – meant to be quick off-the-cuff breakdowns and summaries as we read through S-1 filings in our areas of interest (data, ML and AI, mostly), as opposed to any particularly in-depth analysis. For prior teardowns, see Klaviyo, Confluent, C3, Palantir, Snowflake. This one is written in collaboration with my close colleague Aman Kabeer.
For anyone interested in a little bit of historical context, Michael James, co-founder, had presented at my monthly Data Driven NYC event in February 2020: Designing an AI Supercomputer.
HIGH LEVEL THOUGHTS
The chip wars. There’s a fun David vs Goliath dimension to the Cerebras IPO story as they “come at the king”, NVIDIA (mixing metaphors from both the Bible and The Wire is one the things we’re proudest of, in our S-1 teardown series). While NVIDIA owns 90% of the market, there’s a plethora of other competitors both big (AMD, Intel, Microsoft, etc) and emerging (Groq, SambaNova, etc). Reading through the S-1s, Cerebras makes exciting performance claims that should position it well from a product perspective: 10 times faster training time-to-solution, and over 10 times faster output generation speeds than other top GPU-based solutions for inference (which enables real-time interactivity for AI applications and agents).
Timing is everything? Of course AI is hot, hot, hot, and Cerebras plays in a very strategic part of the AI market (the well-documented AI infrastructure build, happening right now), at a very sensitive time (the even more well-documented GPU shortage, which may or may not last). Therefore, this indeed feels like there’s a very interesting window of opportunity for Cerebras to go out, despite overall market uncertainty (elections, etc), and a business that is less fully baked than some would-be IPO candidates (Stripe, Databricks).
Return of the small IPO? In the grand scheme of things, while it’s growing very fast, the company is reasonably early in revenue – $136 million in revenue in the first six months of 2024, and $78.7M for the fully year 2023. In many conversations with both sell side and buy side people, we’ve heard many times that anything below $400M in ARR is going to be considered “subscale”, with some market participants (like Philippe Laffont of Coatue) saying that $1B in ARR is the minimum number. Now, many investors are unhappy with this state of things, and argue that the market should allow smaller companies to go public – including, interestingly Brad Gerstner of Altimeter (investor in Cerebras) and Bill Gurley of Benchmark (Eric Vishria of Benchmark led the first round in Cerebras and has been on the board ever since), putting their money where their mouth is.
Regardless, given the scale of competitors Cerebras is going after, it makes sense for Cerebras to access the deep pockets of public markets as soon as possible.
Very much in line with the arguments of those advocating for smaller companies to go public, Cerebras may turn out to be a good example of a company where all the growth and value creation was not captured by private markets.
Growth or profitability? The market has flip flopped from a priority standpoint over the past few years, from ‘growth at all costs’ being rewarded in the 2020 & 2021 software heyday to ‘efficiency efficiency efficiency’ in 2022 & 2023. Cerebras will be a great case study, particularly amidst a perceived return to favoring growth as the predominant factor. The company is scaling incredibly rapidly (220% Y/Y from 2022-2023), but still inefficiently (-136.3% Non-GAAP Operating Margin in 2023), with a $66.6 million net loss for the first six months of 2024, compared with a wider $77.8 million net loss in the first half of 2023.
Hardware vs software: Cerebras is clearly going after NVIDIA, with impressive product performance. However, a big part of NVIDIA’s competitive advantage lies not just in the hardware, but also in the software – CUDA, both a computing platform and programming model enabling developers to program NVIDIA GPUs directly. CUDA has led to strong lock in within the developer community and it’s considered to a key component of NVIDIA’s overall value. While Cerebras certainly has a software business (see below), it will be interesting to see to which extent markets value it as a hardware company vs hardware/software a la NVIDIA.
Revenue concentration: in our teardown of C3 IPO, we were noting how revenue for C3 was highly concentrated, with the top two customers accounting for 26% of revenue. Well, Cerebras is taking this to a whole new level, with 87% of Revenue in the first half of this year is from just one customer, G42 in the UAE (see details below). Now, the nature of the chip business in the cloud era arguably lends itself to revenue concentration (smaller number of customers with deep pockets that will place very large orders, vs every company buying its own GPU), but it will be interesting to see how markets react.
..More
Post of the Week

News Of the Week
OpenAI raises $6.6 billion in largest VC round ever

OpenAI announced on Wednesday it has completed its long-anticipated funding round, raising $6.6 billion in the largest venture capital deal of all time, which values the company at $157 billion.
The intrigue: OpenAI is planning to shift to a for-profit structure and investors can ask for their money back if it hasn't completed those changes in two years, Axios has learned.
Driving the news: Joshua Kushner's Thrive Capital led the round, and was joined by Microsoft, Nvidia, SoftBank, Khosla Ventures, Altimeter Capital, Fidelity, Tiger Global and MGX.
Not taking part, a source confirms, is Apple, which reportedly had been in talks to invest.
OpenAI's deal tops the $6 billion raised earlier this year by Elon Musk's xAI.
The big picture: OpenAI is effectively transforming from a nonprofit lab to a product-focused company — a move that has attracted investors, but likely contributed to an exodus of many long-term employees.
Last week, CTO Mira Murati and two top researchers announced they were leaving the company amid multiple reports of a culture clash between the product and safety teams.
Internal debates about speed and safety have grown louder in the 10 months since the firing and rehiring of CEO Sam Altman.
OpenAI disputes any suggestion that it is deprioritizing safety even as it moves toward a for-profit model.
What they're saying: "The new funding will allow us to double down on our leadership in frontier AI research, increase compute capacity, and continue building tools that help people solve hard problems," OpenAI said in a blog post.
The bottom line: OpenAI continues to grow its revenue, but the giant investment reflects how its costs are also rising,
Go deeper: OpenAI speeds ahead as it shifts to for-profit
Private Market investing is huge but still remains broken.
Oct 02, 2024
When I co-founded Allocate in 2021, it was based on a 20 year observation that 1) Companies are staying private longer 2) Private markets started to become as important as the public market for investors (There are reportedly 108K software companies today but only 3% are public) and 3) Investors and GPs are still relying on outdated tools to deploy capital and to raise capital.
So despite the growth of the private markets, the increased fragmentation on both sides of the ecosystem (new manager entrants and the growth of high net investor interest) have created a system wrought with inefficiency and opacity.
Private market assets under management (AUM) have surged past $13 trillion, with projections to exceed $25 trillion by the decade's end. This is not suprising given the protracted time companies stay private (for tech companies <4 years to 9 years+), the reduction of publicly traded companies, and historical return and diversification benefits of private markets.
However, the current system does not support efficiency.
Finding, performing due diligence, and accessing the right fund managers has become an exhaustive, time-consuming endeavor for LPs, amplified by the market's lack of transparency.
Beyond this, managing a private investment portfolio effectively is a significant challenge. Building a well-constructed portfolio, tracking investments and gaining key insights, and ensuring that new opportunities align with an investor’s evolving goals is nearly impossible without a structured, data-driven approach.
For most investors, this results in private market investing being more ad-hoc than programmatic, which often leads to performance that is not adequate to justify the illiquidity and risk of private market investing.
On the other side, fund managers face similar inefficiencies. They struggle to efficiently connect with the right limited partners, they often default to higher investment minimums that exclude a broad pool of potential investors and rely on outdated tools for LP reporting and communication.
What IF this wasn’t the case?
While I haven’t spoken as much publicly as I should have about what we are up to at Allocate, I have had so many people ask me what we actually do and don’t (note to self: do a better job on this).
Here are a few TLDR points:
Allocate is not a fund of funds. While I respect so many of the great FoF managers, we are solving for something different through technology.
Private market investing has the potential to mirror public investing when it comes to access, portfolio transparency, and liquidity.
Artificial intelligence and data driven models will transform the private markets.
Private market investing in not a one size fits all. Tailoring and Personalization are the key in the future.
Allocate: Modernizing the private market experience
At Allocate, we are continuing to build a lifecycle platform to bring this vision to life, with purpose-built software and data at the core.
While we started our journey by enabling responsible investing in opaque asset classes such as venture capital (and now Private Equity as well), we continue to believe that solving the private market pain points requires a focused software and data-first approach to provide the necessary tools for investors to efficiently achieve the best outcomes.
What does this mean?
For Investors:
Imagine:
Imagine discovering and analyzing highly personalized private investment opportunities that, powered by data and augmented by AI, recommend the opportunities that best account for your current portfolio and portfolio goals.


26 new YC-backed startups to keep an eye on
Oct 02, 2024
I love demo days. There’s nothing quite like watching dozens of smart folks — often pretty early in their careers! — show off something that they built and really believe in. It’s akin to a very grown-up version of show-and-tell, but instead of presenting to a class, the founders are showing off their work to the global venture capital industry en masse.

Something else fun about demo days is picking a fantasy team of sorts — the startups that you think are the most exciting, enticing, whacky and fun, or otherwise interesting. I used to help write TechCrunch’s coverage of demo days, and even though I have left the mothership, I can’t break this particular habit.
So, here are the 26 recent Y Combinator graduates that I am most excited about from the recent cohort:
Spaceium: In-orbit refueling and repair. Nearly $90 million in “binding commercial contracts” and $1.2 billion in less firm demand. The company claims that it has “successfully tested our hardware, which will launch to space next year.” This company is hot shit in my books because the number of satellites in orbit is scaling vertically, lower launch costs and faster cadence via SpaceX is making the space economy viable in ways that it never was before, and all that work is going to need service stations. Enter Spaceium.
Lumen Orbit: What sort of satellites might Spaceium support? How about Lumen Orbit’s data centers in space? The race to build ever-larger digital brains is a land-based fight today. But data centers are going to crop up everywhere they might have an edge; underwater for greater cooling, or, perhaps, in space where they can get around national boundaries and absorb winsome solar power? Lumen isn’t making small plans, and I personally want to host my websites from space servers.
See also: Network Ocean, which is building underwater data centers.
Entangl: Speaking of ever-larger, ever-more-complex data centers, how about a tool that uses AI to help design data centers? Entangl has bigger plans than merely using AI to help build more server clusters more quickly, but it’s applying its software to an obvious growth market in the near term. With Entangl I worry that it could get snapped up by a major cloud provider before reaching material scale, but with TAM this big it’s hard to not like what Entangl is cooking up.
Exa Laboratories: I am familiar with polymorphic encryption — thanks, Anshu — but polymorphic computing was new to me. The idea behind Exa is building chips that can change their setup to better support different AI models. Or as Exa puts it, “hardware that can reconfigure itself for each AI model, making it both faster and more energy-efficient than traditional GPUs.” No idea if this will work. But any startup that can snag even a few points of the AI chip market is going to be worth $100 billion, so why not Exa?
OrgOrg: As this company exists today, I don’t find it too exciting, but it’s working on a problem that I really care about. If you watch any big tech company over time, you’ll notice a pattern in how they operate. First, they go through a period of revenue growth and rapid hiring, powered by some external trend. Then, when that trend slows, they get Very Serious about pursuing a flatter organizational structure so that they can move more quickly again. It never really works. OrgOrg wants to build software to help teams productive as overall staffing levels rise. Someone is going to crack this problem. Maybe it’s OrgOrg.
Melty: Chat-based code generation. Using AI to shit code is not at all novel, and is perhaps one of the most competitive zones for startups in the market today. (Which is great, given how much code we humans need to generate every year!) Melty takes a different approach is chat-based, “where every chat message is a git commit.” The goal with Melty — somewhat akin to Qodo — is to better integrate with a developer’s workflow, and generate more accurate, useful, and less buggy code. Melty is also open-source, which rules.
Patched: Speaking of open-source startups, Patched is building open-source “workflow automation for dev teams.” I am not going to pretend that I’ve written much code at all in the last ten years, so I’ll avoid trying to tell you how that might work. But, I doubt that all AI-related productivity gains for devs are going to land at the code-generation level. And this looks really cool.
Void: Sticking to the open-source coding theme, let’s talk about Void. It’s targeting Cursor in its branding, one of the better-known names in AI-powered code generation. However, it’s taking a more open approach that includes a neat privacy twist, promising that it does not send “code to an external API,” which some companies might prefer.
See also: Haystack Software (codebase visualization) and Palmier (an AI-native alternative to GitHub)
Saldor: This is Darth Startup, kinda. Saldor is a tool that will do web scraping for you. Need data for that AI project? Saldor can help you get it! CO has written about copyright, and the value of online data. Saldor is, from what I can see, coming at the issue from the other side of the fence. That makes the startup an interesting wager; if copyright winds up kaput in the AI age, Saldor could clean up. Or, not. Either way, one to watch.
See also: Voker (helps product-types “build AI features in minutes without involving engineers”)
The World Around Us: Some startups in the most recent YC batch took a rather earthy approach to finding a market. MineFlow wants to predict the space of mineral deposits, Anthrogen wants to use “genetically modified bacteria and optimized enzymes” to turn airborne carbon into “larger, more complex molecules,” while Sorcerer is building weather balloons that can collect oodles of data.
What About Robotics? Fear not, several stood out from the larger Summer 2024 cohort. Sensei, ScaleAI for robotics data, Ember Robotics, Datadog for robotics, and Weave Robotics, robot assistants for the home coming in 2025.
And the rest: Kontingo’s use of the USDC stablecoin for Latin American neobanking is cool; if Conductor Quantum can really bring quantum computing to trad silicon it’ll be massive; TaxGPT is vertical AI for accountants, a market where automation should absolutely shine; dmodel wants to help folks look into AI models; and Stormy.AI, an AI system that watches your computer and learns from you directly.
Global Funding Slowed In Q3, Even As AI Continued To Lead
October 3, 2024
![Illustration of a tidal wave - Global - Quarterly Reports [Dom Guzman]](https://substackcdn.com/image/fetch/$s_!Tlwq!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F0d72d2ec-14f1-42f6-97a5-14231a92b515_900x506.jpeg "Illustration of a tidal wave - Global - Quarterly Reports [Dom Guzman]")
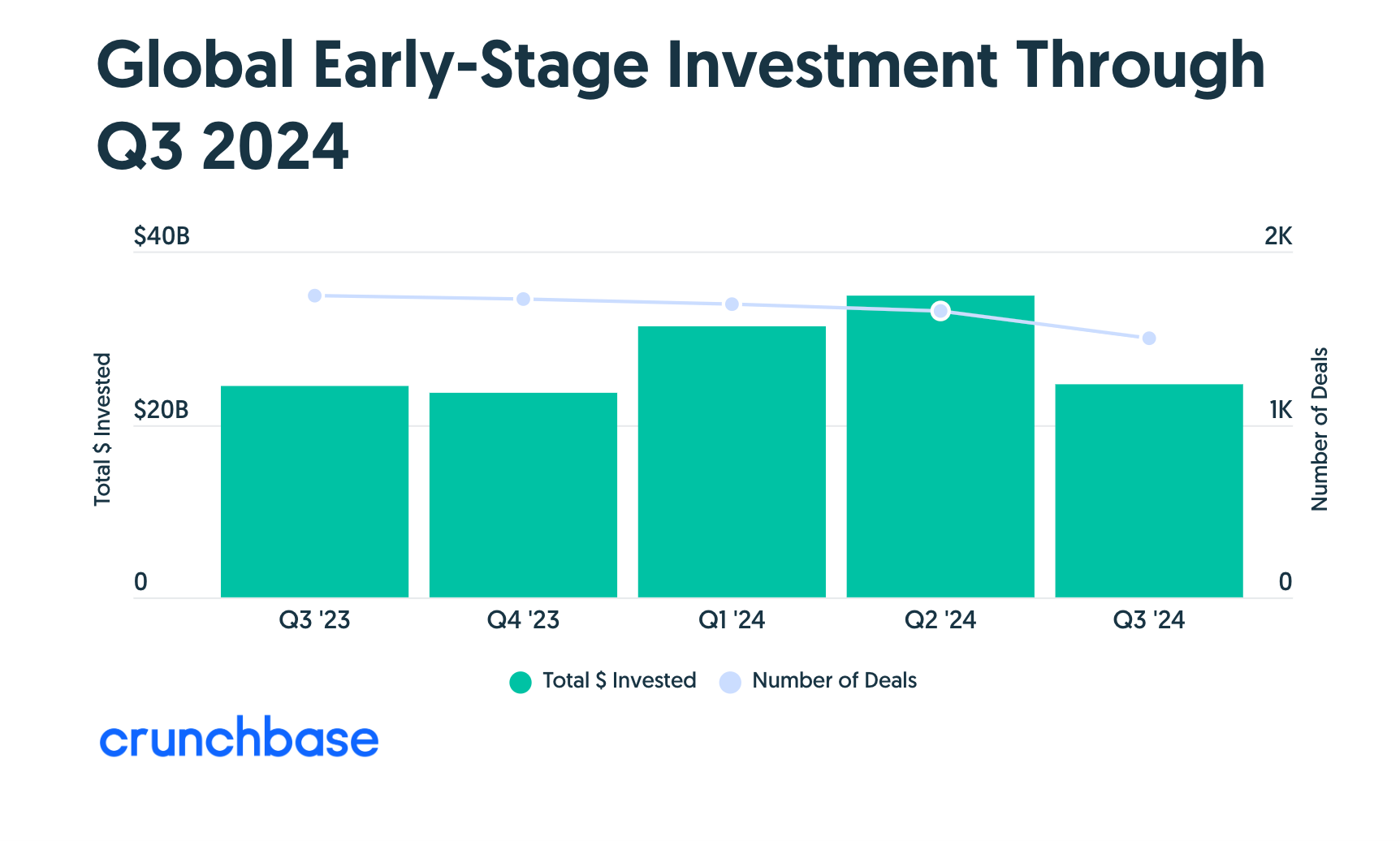
Global venture funding in the third quarter of 2024 reached $66.5 billion, Crunchbase data shows. That’s down 16% quarter over quarter and 15% year over year from the $78 billion invested in Q3 2023.
We are now nine or 10 quarters into the current startup funding decline. This past quarter was the second below the $70 billion mark since the start of the current venture funding downturn, according to Crunchbase data. Outside of Q4 2023 and this past quarter, one would need to go back to 2017 to find another quarter below $70 billion.
But Q3’s numbers don’t necessarily signal a further pullback in venture funding moving forward, as we’ve seen large fundings fluctuate quarter over quarter this year and last, skewing overall numbers.
Table of Contents
Large, late-stage rounds lead drop
In Q3, the steepest decline year over year was seen in late-stage funding and was most evident in the largest rounds, those $500 million and above.
The concentration of venture dollars that went to the largest rounds — those of $100 million or above — was also slightly lower in Q3, at about 46%, compared to about 50% in Q2 and the third quarter of last year.

AI led
AI was the top sector by dollars invested in the third quarter, with funding to artificial intelligence startups reaching close to $19 billion, or 28% of all venture dollars, Crunchbase data shows.
Funding to companies in AI has grown in 2024 by both absolute dollars invested and proportion. Last quarter was the second-largest quarter for AI funding since the mainstream launch of OpenAI’s ChatGPT in November 2022, behind only Q2 2024.
AI surpassed healthcare and biotech, the second-largest sector, which raised more than $15 billion.
Hardware, the third-largest sector, raised more than $13 billion. Financial services companies, meanwhile, raised close to $8 billion.
The largest funding deals in Q3 were all over $500 million:
Waymo, an autonomous driving service and Alphabet subsidiary, raised $5 billion from its parent company;
Defense tech startup Anduril Industries raised $1.5 billion in a round led by Founders Fund and Sands Capital Ventures;
Safe Superintelligence, an AI research lab founded by OpenAI founder Ilya Sutskever, raised $1 billion. The lead investor was not disclosed but Andreessen Horowitz, Sequoia Capital, NFDG Ventures and DST Global participated in the funding;
Legaltech startup Clio raised $900 million led by New Enterprise Associates; and

Late-stage down YoY
Late-stage funding reached $34.7 billion, flat quarter over quarter and down from $46 billion in the third quarter of 2023, Crunchbase data shows. The biggest change in Q3 from a year earlier was a decrease in the amount invested in deals above $500 million.
Last quarter, large fundings went to autonomous driving, defense tech, professional services, semiconductor and AI model companies.

Early-stage flat YoY
Early-stage funding reached $24.7 billion, down quarter over quarter in large part due to the $6 billion Series B funding to Elon Musk’s OpenAI competitor xAI in the second quarter, which skewed those numbers upward. (On Wednesday, two days into Q4, OpenAI officially announced its own $6.6 billion raise that values it at more than $150 billion.)
Year over year, early-stage funding was flat. By far, large early-stage rounds were dominated by AI and biotech.
Seed down
Seed funding reached $7 billion in Q3, down quarter over quarter and year over year, Crunchbase data shows. (Though it’s worth noting, there is typically a gap as many seed fundings are often added to the Crunchbase dataset after the close of a quarter.)
The majority of seed funding — around $6.8 billion — was invested in fundings of $1 million and above, across more than 1,500 companies globally.

Through Q3
Year-to-date, venture funding is down around 7% year over year.
Based on an analysis of global funding through the third quarter compared to the same timeframe in 2023, seed funding year to date appears flat, (but is likely to show an uptick as seed rounds are added after the quarter-end), early-stage funding is trending up by around 10%, and late-stage funding is down around 20%.
While venture seems to be in a holding pattern year over year, the underlying dynamics of the industry are shifting as fundraising for venture funds slowed down in 2024. With fewer funds, the impact will be seen at the earliest stages of funding moving forward.
Carta’s First Cut—State of Private Markets: Q3 2024
Author: Ashley Neville
Published date: October 4, 2024
Initial data from Q3 2024 shows median pre-money valuations and cash raised remained steady compared to previous quarters across the U.S. venture ecosystem.
Every quarter, Carta releases information on the startup ecosystem in our State of Private Markets report. It can take a few weeks for rounds to be recorded on our platform, so we produce a full analysis after we get the final numbers.
In the meantime, we publish a “first cut” of data as close to the end of the quarter as possible. This initial analysis focuses on round valuations and cash raised across the venture stages.
Preliminary look at Q3 data for U.S. startups:
Cautious optimism in valuations: Following on modest gains in Q2, median pre-money valuations remained comparable with previous quarters. In rounds that experienced slight declines quarter over quarter, the median stayed above Q1 levels. Series C showed markedly positive movement.
Consolidation in round sizes continues: The median cash raised last quarter remained consistent with figures from Q1 and Q2, hinting at stability in funding levels. Series E+ returned to Q1 levels after a notable spike in Q2.
While final numbers on total rounds and capital raised are not yet available for Q3, preliminary insights suggest that overall fundraising will stay in line with early 2024.
Seed

Series A

Series B

Series C

Series D

Series E+

To see the valuations and round size data below split into primary and bridge round figures, you can download this addendum now.
Early can be tantamount to being wrong
Or, Q3 VC data in context.
Signal Rank Corporation - Rob Hodgkinson
Oct 03, 2024
Q3 VC funding data is in. There were 1,175 announced seed rounds globally in Q3 2024, down 25% compared to Q3 2023 (or down 48% compared to 2021). Similar patterns were seen at Series A, Series B & Series C (all down c.15% vs Q3 2023).
The data suggests VC is in flux. The venture capital industry is currently holding its breath. Waiting for the excesses of the ZIRP bubble work their way through the system. Waiting for the outcome of the US election. Waiting for exits.
But, more than anything else, the venture capital industry is looking for the next grand narrative. The great hope is AI. AI will wipe away the sins of the 2020/21 bubble and bring back the feelgood factor in the industry.
Here’s a characteristically understated slide from a recent SoftBank presentation (unclear whether or not this is to scale):
Figure 1. SoftBank’s Evolution of Humanity

There is consensus (always dangerous) that AI is the next big technology platform. The big question is around timing. The capital deployed into AI and the rapid adoption rate of products is already eye-watering. But enterprise rollouts of AI solutions remain at the experimental phase. And best not to mention the current unit economics of running foundational models. In other words, it is early in the AI era.
VCs have tried their best to look relevant with the arrival of this new platform technology. It’s just that the first phases of the AI cycle have not favored VCs & startups. Not yet.
Even the VCs who have benefited thus far from the AI boom (e.g. Khosla Ventures) have had to pull some fairly unnatural maneuvers. See the funky 100x capped structure of the OpenAI investment, as well as the existence of OpenAI’s unusual non-profit entity. Or the apparent round-tripping between Cerebras & G42. The Economist talks about how “generative AI is bringing disruption to the home of America’s disrupters-in-chief. Enjoy the Schadenfreude.”
With AI, we have been in the early part of the platform cycle that requires huge capex investments by the hyperscalers to build the foundational infrastructure layers (data centers, hardware & core algorithms), on top of which next gen VC-backed software can be built. VC is rocket fuel which *in general* (don’t @ us with names of successful hardware exits) is better suited to high margin & scalable software (because software can be a more capital efficient play to deliver the largest power law returns required to make the whole thing make sense).
VC was not the appropriate financial instrument for the initial phase of the AI game. The VC industry’s pockets are not deep enough to play in the foundational layer. A $100m Series B looks cute next to a $100bn foundational model.
Beyond seed & Series A, AI’s capital requirements and its epic valuations are pricing out almost all VCs at growth stages. This week even saw two funds “give back” later stage capital to focus instead on earlier stage opportunities. CRV decided not to deploy $275m from its $500m opportunity fund. PeakXV trimmed its 2022 fund by $465m for similar reasons.
This is a movie we have seen before. Aileen Lee wrote a piece last week about how it takes time for the startup winners to displace the incumbents in every technology cycle. Maggie Basta echoed this here by looking exclusively at infrastructure software companies in each cycle (including AI). We agree. It’s early.
We want to take a slightly different approach to make the same point, by looking through the lens of the layers for each cycle in previous platform shifts, like the rise of the internet, cloud computing & mobile. Each of these shifts went through a similar trajectory: heavy capital expenditure investments at the infrastructure & hardware level, followed by a wave of middleware & application software that capitalized on the newly available technology. AI is currently at a similar inflection point.
This is one possible explanation for the slowdown in funding in Q3. VCs understood these dynamics from previous cycles. And have been waiting.
Let’s revisit some history.
VC slowdown in context
Capital deployment in venture capital has slowed substantially since 2021. Carta has shown how the 2022 vintage has only seen 43% deployed after 24 months, which is lower than any vintage from 2017 onwards (Figure 2). (This also implies that there is tremendous dry powder to be deployed, at the right time).
Figure 2. 2022 vintage deployment pace

With Crunchbase’s dataset, we see that the number of rounds at each stage continues to decrease. There were only 224 Series Bs globally in Q3 2024 (Figure 3). An annualized number of 894 is a level of Series Bs not seen since 2013 (787).
Figure 3. Quarterly Series Bs since 2019 from signalrank.ai

The recent spike in the average round sizes shows an underlying tale of two cities. AI companies are raising enormous Series Bs at punchy valuations, while the rest of the market fights for any remaining capital. Coatue demonstrated how AI investments represent c.3% of VC rounds in 2024 but 15% of total capital (Figure 4).
Figure 4. Coatue’s comparison of AI & non-AI rounds in the US in 2024
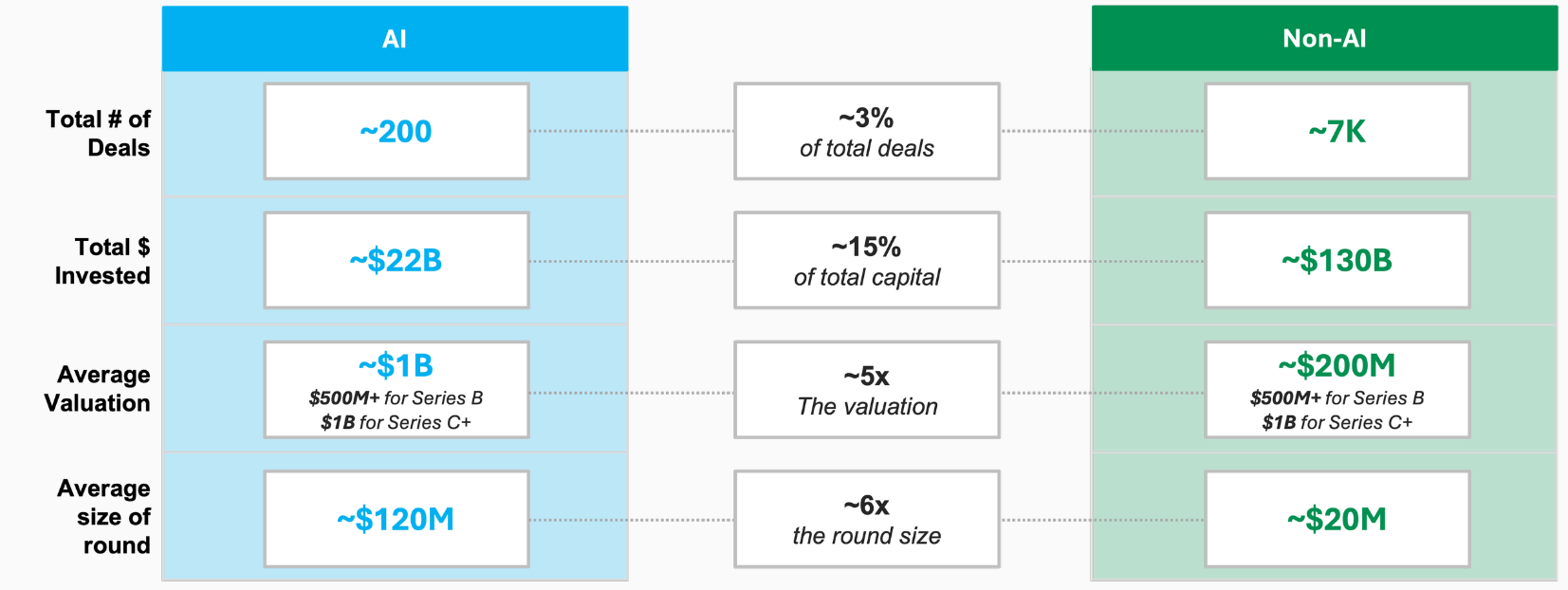
The marked slow down in Q3 also suggests that the sugary high of the GenAI hype cycle is starting to wear off. VCs have placed their bets to signal to the market & LPs their AI chops.
In fact, we will argue that most (if not all) of these VC bets are still too early. Maybe the slow down in round numbers is VCs recognizing that we are not yet at the power law vintage for AI investments?
A Venture Capital Firm Does Something Rare: Give Money Back
CRV, based in Silicon Valley, plans to return to investors $275 million because the market for mature start-ups has soured.

Four of CRV’s partners, clockwise from rear left: Reid Christian, Murat Bicer, Saar Gur, and Max Gazor at the firm’s office in Palo Alto, Calif.Credit...Ryan Young for The New York Times
Reporting from San Francisco
Oct. 2, 2024
Venture capital firms raise money — lots of it — and invest it in start-ups in hopes of generating big returns. One thing they rarely do is give the money back.
Yet that is what CRV, one of the industry’s oldest firms, is planning. The firm will tell its investors this week that it will return the $275 million that it has not yet invested from its $500 million Select fund, which is designed to back more mature start-ups.
The reason, four of the firm’s partners said in a joint interview, is that market conditions have changed for the worse. The valuations for start-ups are too high relative to their potential for a payoff, the partners said.
CRV’s decision is part of a reset that is happening around the venture capital industry after the go-go years of the pandemic. In 2020 and 2021, many start-ups and investment firms raised outsize funding, expecting the boom to keep going.

