


No Andrew this week, so no video conversation.
Contents
Editorial: What are the Economics of an AI Native Internet? Who Pays Whom?
Essay
AI
Cutting-Edge AI Was Supposed to Get Cheaper. It’s More Expensive Than Ever.
Elon Musk Just Delivered a Ringing Endorsement of the iPhone’s Staying Power
Made by Google 2025, AI Trade-offs, Google and the Long-Term
OpenAI acquires product testing startup Statsig and shakes up its leadership team
Mistral Set for $14 Billion Valuation With New Funding Round
OpenAI set to start mass production of its own AI chips with Broadcom
Media
Venture
The IPO Market Is Opening Up. These 14 Companies Could Be Next.
Anthropic Nearly Triples Valuation To $183B With Massive New Funding
Anthropic Valuation Hits $183 Billion in New $13 Billion Funding Round
Benchmark’s Peter Fenton Isn’t Ready to Call This an AI Bubble
From Frustration to Conviction: What led to starting Allocate and our $30.5M Series B
Jack Altman & Martin Casado on the Future of Venture Capital
GeoPolitics
Regulation
What the Fixes for Google’s Search Monopoly Mean for You: It’s a ‘Nothingburger’
Google Must Share Search Data With Rivals, Judge Rules in Antitrust Case
Read our statement on today’s decision in the case involving Google Search.
Washington doubles down on Big Tech antitrust cases despite Google setback
Tesla Board Proposes Musk Pay Package Worth as Much as $1 Trillion Over Decade
Google Is Fined $3.5 Billion for Breaking Europe’s Antitrust Laws
Anthropic Agrees to Pay $1.5 Billion to Settle Lawsuit With Book Authors
Education
Editorial: What are the Economics of an AI Native Internet? Who Pays Whom?
The Internet is responsible for about $16 trillion of the global $108 trillion annual GDP. Click the link to see my Perplexity space with the numbers.
The Internet is far bigger than the web. The Internet is made up of all activity on top of TCP/IP and the Domain Name System not only web traffic. This includes all apps, messaging services, online games, payments systems, devices and so on. Only about 40% of the $16 trillion is web related value.
AI is broadly anticipated to be the primary engine of digital and non-web economic growth in the coming decade, with consensus estimates ranging from a modest 1–2% boost to global GDP to transformational impacts of up to $20 trillion, much of which will stem from non-web, embedded, and invisible AI-driven flow
At the same time AI is transitioning to an agentic model where invisible browsers like Browserbase act as the ‘reader’ of web based content, subsumed under an AI interface. So even the 40% currently accounted for by the web will no longer be driven by direct consumer browser use.
This has implications for every stakeholder in the Internet economy.
An AI Native Internet is an Internet where the web, apps, payment systems are all interfaces to a new AI canvas or ‘front door’ accessed via devices - mobile devices, AR devices and new yet to appear ones.
The $16 trillion of current value and the potential $20 trillion new value will all migrate to the AI Native internet, or disappear due to failing to make the transition.
For that reason the question of what the business model of the AI Native internet will be is crucial.
The dream scenario is that AI is universal and free to users. Like web search today. Of course that is already somewhat true but the subscription revenues of OpenAI, Anthropic, Google Gemini and others represent the lions share of revenue today, alongside API triggered token use where developers pay per million tokens consumed for inputs and outputs.
The domination of subscription and token based revenues is a function of the current state of AI. It is hard to impossible for AI to inherit the marketing spend that currently goes to Google and other advertising platforms for reasons we discussed last week.
And it is currently hard for content owners to get the traffic from AI, and hence the revenues, that they get from the web and app economy today. Again we discussed why last week, but broadly AI does not send much traffic to content owners.
This week Matthew Prince from Cloudflare was interviewed about a pay per crawl proposal using an http 402 technology that would enforce payment to content owners for a crawl. He suggests $1 per year per MAU(Monthly Active User), from the LLMs to a pool. Then this would be distributed to the content owners. I assume there would be some math creating a pro-rata payout according to some measure of value exchanged.
There is a lot to grasp here, but let’s assume that happens and all 4 billion humans with smart phones are in the MAU, that would create a $4 bn pool annually. It is only a small proportion of $16 trillion. So pay per crawl is definitely a feature of a business model for an AI Native Internet, but it is not the full model. Web advertising alone is a $667 billion portion of current Internet revenue, so one can see that $4 billion is good start, but small.
The logical first question is, how much of the $667 billion from advertising can migrate to this new AI native internet where the web is subsumed under AI and its agents?
For AI that is a pressing question as this week’s articles show that the cost of running AI, especially with reasoning and agents is rising, not falling.
The model we (all builders) should build is an AI Native Internet that is free for users, paid for publishers, and yes, paid for AI’s in return for the traffic they send and the value they create from that. It seems it might collectively be a $16-40 trillion economy in the years ahead.
The virtuous loop we laid out last week moves closer to this: identity for agents, attribution for links, settlement for outcomes. Cloudflare’s pay-per-crawl plus a neutral clearing function (accounting, registries, enforcement) can sit beside an AI-era CPC/CPA/CPM model.
Importantly, AIs shouldn’t only pay—they should also get paid. When they route high-intent traffic that converts on content owner’s sites. This aligns incentives: better answers send better clicks, with auditable receipts. Indeed AIs would earn a lot more than they pay because the crawls revenues they pay out would dwarf the share of the entire economy they are paid.
Tools like Anthropic’s MCP and unified metadata layers make those receipts credible by stitching permissions, provenance, and business context into the workflow.
I believe this needs a single trusted third party being paid by the ecosystem to run such a set of services just as the domain name system has a root server run by ICANN, the AI Native Internet would benefit from a root monetization system.
The .com system is managed by Verisign. Its revenue annually is $1.56 bn of the $16 trillion economy. Add Google’s share of advertising and the share of others providing all of the services, and it is hard to get infrastructure to be even 10% of the $16 trillion. A monetization infrastructure for AI would combine several roles and would represent a tiny fraction of the total value created.
What to watch next
Whether Google offers a true opt-out for AI Overviews—and how fast regulators push interoperability beyond search data.
Adoption of “402 Payment Required”–style signals and pay-per-crawl at scale, turning rights into programmable rails.
If DOJ’s ad-tech remedies force structural change this fall although the transition to AI will render this irrelevant.
Whether chip moves (OpenAI–Broadcom) and model routing meaningfully bend inference COGS for all, reducing AI costs (against the current trend).
The long arc still points to the same equilibrium: free (or near-free) AI for users; real money to publishers for training and traffic; and revenue for AIs that create measurable value in the handoff. Build the identity, registry, and clearinghouse—and everybody wins.
And a final note. The Anthropic settlement with book publishers this week ($1.5 billion) is being widely misinterpreted. Anthropic was not sued for reading publicly available books. And it was not sued for reading books it purchased. The suit was due to the fact that Anthropic read stolen books, and hence breached copyright in the act of stealing. Had it paid for the books no suit would have succeeded. The case does not indicate that copyright protects legally acquired content from being a source of training data. Legally acquired content can be used for training unless the law changes, and there is no indication of that.
Essay
AI and jobs, again
Noahpinion • August 30, 2025
Essay•AI•LaborMarket
The debate over whether AI is taking people’s jobs may or may not last forever. If AI takes a lot of people’s jobs, the debate will end because one side will have clearly won. But if AI doesn’t take a lot of people’s jobs, then the debate will never be resolved, because there will be a bunch of people who will still go around saying that it’s about to take everyone’s job. Sometimes those people will find some subset of workers whose employment prospects are looking weaker than others, and claim that this is the beginning of the great AI job destruction wave. And who will be able to prove them wrong?
In other words, the good scenario for the labor market is that we continue to exist in a perpetual state of anxiety about whether or not we’re all about to be made obsolete by the next generation of robots and chatbots.
The most recent debate about AI and jobs centers around recent college graduates. Derek Thompson wrote a post suggesting that a slowdown in job-finding for recent college grads could be the first sign of the job-pocalypse. A number of news articles ran with this story and treated AI job destruction as a proven fact, but some pundits pushed back on the narrative, citing various data sources. I wrote about the whole controversy in this post: Stop pretending you know what AI does to the economy.
Then, Sarah Eckhardt and Nathan Goldschlag of the Economic Innovation Group, a think tank, came out with some research that found no detectable effect of AI on recent employment trends. (I covered this research in my last roundup post.)
Eckhardt and Goldschlag looked at several measures of which jobs are more “exposed to” AI. They found that for three of the five exposure measures they looked at — including their preferred measure, from Felten (2021) — there was no detectable difference in unemployment between the more exposed and the less exposed workers. But for two of the measures, there was a small difference, on the order of 0.2 or 0.3 percentage points:
The EIG researchers conclude that AI probably isn’t taking jobs yet, and if it is, the effect is still very small at this point.
Eckhardt and Goldschlag were wise to title their research note “AI and Jobs: The Final Word (Until the Next One)”. Indeed, the next word on the topic came out almost immediately, in the form of a paper by Brynjolfsson, Chandar, and Chen, entitled “Canaries in the Coal Mine? Six Facts about the Recent Employment Effects of Artificial Intelligence”.
Brynjolfsson et al. do something very similar to Eckhardt and Goldschlag — they use two measures of how exposed a job is to AI, and then they compare recent employment trends for more and less exposed workers. Their finding is startlingly different than that of the EIG team:
“Our first key finding is…substantial declines in employment for early-career workers (ages 22-25) in occupations most exposed to AI, such as software developers and customer service representatives. In contrast, employment trends for more experienced workers in the same occupations, and workers of all ages in less-exposed occupations such as nursing aides, have remained stable or continued to grow.
“Our second key fact is that overall employment continues to grow robustly, but employment growth for young workers in particular has been stagnant since late 2022. In jobs less exposed to AI young workers have experienced comparable employment growth to older workers. In contrast, workers aged 22 to 25 have experienced a 6% decline in employment from late 2022 to July 2025 in the most AI-exposed occupations, compared to a 6-9% increase for older workers. These results suggest that declining employment AI-exposed jobs is driving tepid overall employment growth for 22- to 25- year-olds as employment for older workers continues to grow.”
The $20/Month Software Revolution
Tomtunguz • August 30, 2025
AI•Tech•Vibe Coding•Low Code NoCode•Software Development Tools•Essay
Software development has operated within established boundaries for decades, with clear divisions between those who code & those who don’t.
But what happens when those boundaries dissolve overnight, & anyone can build functional applications for the price of a monthly streaming subscription?
For twenty years, professional software development meant specialized teams, lengthy sprints, & rigorous adherence to architectural best practices. Companies invested months in planning, weeks in development cycles, & substantial resources in quality assurance. The barrier to entry remained high, protecting established players & maintaining predictable market dynamics.
AI coding tools have shattered this equilibrium. Cursor, Lovable, & similar platforms now enable non-technical founders to prototype working applications in hours rather than months. The result is an explosion of vibe coding: intuitive, rapid application development that bypasses traditional workflows entirely.
This shift has created a fascinating paradox for founders & investors. The current landscape rewards speed over sophistication, with spaghetti-coded solutions often outpacing polished alternatives to users’ laptops. Yet this same accessibility threatens to commoditize software development itself, raising questions about where sustainable competitive advantages will emerge.
The answer lies in recognizing this period as history’s largest distributed market research experiment. Thousands of individual users are discovering optimal AI-enhanced workflows through trial & error, essentially crowdsourcing the future of software development. Smart players should treat this chaos as intelligence gathering rather than noise.
The strategic opportunity exists in two phases.
First, embrace experimentation during this chaotic period because the cost is minimal, & the learning is invaluable. Second, prepare for consolidation by identifying workflow patterns that demonstrate real user adoption & commercial viability.
The current vibe-coding era won’t last forever. Eventually, brilliant practitioners in each domain will distill optimal workflows from this experimentation, commercialize them, & establish new industry standards.
The companies that recognize these emerging patterns earliest & build robust, scalable versions before the market standardizes will define the next generation of software development tools.
The glee of solving problems with $20-per-month AI tools represents more than convenience; it signals a fundamental restructuring of how software gets built & who gets to build it.
Opinion | AI Won’t Eliminate Scarcity
Wsj • September 2, 2025
Essay•AI•Scarcity•Labor Markets•Automation

Jobs in market economies will disappear only when unmet human desires disappear.
AI will change how we build startups -- but how?
Andrew Chen • September 3, 2025
Essay•AI•Home Screen Test•Defensibility•AI Agents
Thesis and Early Signal
The piece argues we’re in the “golden age of AI,” yet adoption in everyday software remains nascent. The litmus test is the “Home Screen Test”: out of a typical 4x7 grid of 28 phone apps, how many are truly AI‑native—and how many were built with AI coding tools? Beyond obvious LLM apps, the answer is near zero, highlighting a vast, untapped opportunity. Today’s shift amounts to “I Google less and prompt more,” but the author contends we’re just at the beginning of how AI will reshape both products and the companies that create them. “We still don’t know a lot,” he writes, framing the post as a map of open questions rather than definitive predictions.
Open Questions That Will Shape Startup Building
Team size and leverage: Will AI shrink headcount via 1000x leverage and agentic workflows—e.g., one person supervising “1000 agents who code all day”—or will human bottlenecks like taste, design, and operations still force hiring?
Defensibility in a fast-copy world: If AI commoditizes capabilities and replication is instant, what constitutes a moat? Is it distribution and network effects (as the mobile era suggested), relentless iteration speed, or multi‑year, CapEx‑heavy bets (space tech, industrial hardware) that are harder to clone?
Cost to build vs. cost to grow: Models are capital intensive but app development should be cheaper; however, distribution remains expensive. Even when it’s cheap to build, acquiring users can still cost millions, and attention scarcity may be the true limiter.
Team structure: Does the classic triad of product, engineering, and design persist if multimodal AI can translate PRDs and wireframes directly into software? Or do roles collapse into integrated “product engineers” orchestrating model/tool chains?
Geography: Does the Bay Area’s network effect persist or weaken as talent, knowledge, and tooling globalize? If AI makes product creation akin to content creation, will founders emerge everywhere and only aggregate in hubs when needed?
Venture model and stage definitions: If two builders can reach profitability quickly, does venture capital shift from risk to growth capital—and become more globally distributed? Do traditional stage labels (preseed/seed/Series A/B/C) blur as some projects jump straight to later stages while others remain bootstrapped side projects?
Historical Precedent and Organizational Evolution
The argument situates AI within centuries‑long shifts in production and organizational form: from pre‑industrial cottage workshops to industrial factories, corporations, and professional management. It invokes the 1600s rise of long‑distance trade, the limited liability corporation, and the East India Company—whose standing army reportedly reached 260,000—to show how technological leaps often require new business structures to coordinate capital, labor, and risk at scale. By analogy, a world of agents, compute, and models likely demands new organizational architectures beyond today’s startup template.
Two Plausible Futures
Optimistic: AI‑native startups need far fewer people to ship more, with defensibility emerging from breakthrough features rather than mere distribution muscle. Startups become cheaper to build, and hubs like the Bay Area remain magnets for expertise and capital, even as creation globalizes.
Pessimistic (or centralizing): Winners are those with hyperscale data centers, privileged data access, and enormous compute budgets. AI features don’t solve distribution; incumbents retrofit AI into existing products, leveraging their channels to outcompete startups. The key strategic question becomes: “Will incumbents get innovation first? Or startups get distribution first?”
Near‑Term Trajectory
The center of gravity shifts from frontier research to product execution. With foundation models “asymptoting,” the next wave is model‑agnostic builders who orchestrate best‑of‑breed models, layer compelling UI/UX, and embed business logic specific to verticals. Expect a spectrum from horizontal tools to industry roll‑ups, where software plus AI drives consolidation and operational advantage. Speed of iteration, tight feedback loops with users, and the ability to marry domain insight with agentic automation may matter more than training proprietary foundation models.
Implications and Takeaways
Moats may refocus on distribution, data aggregation loops, ecosystem lock‑in, and rapid product cadence—unless a product’s economics are anchored in multi‑year CapEx and regulation‑defined barriers.
Recruiting and org design will prioritize “full‑stack product” talent who can specify, prompt, evaluate, and ship using AI toolchains, while human judgment (taste, ethics, safety, and market intuition) becomes the scarcest input.
Go‑to‑market remains the hardest problem: expect more capital flowing into growth than into initial build, and more experimentation with novel distribution (bundles, embedded workflows, and partnerships).
Geography diversifies creation; hubs still aggregate scaling knowledge and capital.
Venture capital becomes more modular—funding experiments, growth sprints, or roll‑ups—while stage labels get fuzzier.
Key takeaways:
The “Home Screen Test” suggests AI’s consumer impact is still early despite massive promise.
Organizational forms will evolve to harness agentic and multimodal workflows.
Moats in software may erode; defensibility shifts to speed, distribution, and hard‑to‑copy CapEx.
The next wave is model‑agnostic, vertical, UI‑ and business‑logic‑led.
The strategic race pits incumbent distribution against startup innovation velocity.
Almost anything you give sustained attention to will begin to loop on itself and bloom
Henrik karlsson • Henrik Karlsson • September 4, 2025
Essay•Education•Attention•Dopamine•Neuroscience

Brioches and Knife, Eliot Hodgkin, 08/1961
When people talk about the value of paying attention and slowing down, they often make it sound prudish and monk-like. Attention is something we “have to protect.” And we have to “pay” attention—like a tribute.
But we shouldn’t forget how interesting and overpoweringly pleasurable sustained attention can be. Slowing down makes reality vivid, strange, and hot.
As anyone who has had good sex knows, sustained attention and delayed satisfaction are a big part of it. When you resist the urge to go ahead and get what you want and instead stay in the moment, you open up a space for seduction and fantasy. Desire begins to loop on itself and intensify.
I’m not sure what is going on here, but my rough understanding is that the expectation of pleasure activates the dopaminergic system in the brain. Dopamine is often portrayed as a pleasure chemical, but it isn’t really about pleasure so much as the expectation that pleasure will occur soon. So when we are being seduced and sense that something pleasurable is coming—but it keeps being delayed, and delayed skillfully—the phasic bursts of dopamine ramp up the levels higher and higher, pulling more receptors to the surface of the cells, making us more and more sensitized to the surely-soon-to-come pleasure. We become hyperattuned to the sensations in our genitals, lips, and skin.
And it is not only dopamine ramping up that makes seduction warp our attentional field, infusing reality with intensity and strangeness. There are a myriad of systems that come together to shape our feeling of the present: there are glands and hormones and multiple areas of the brain involved. These are complex physical processes: hormones need to be secreted and absorbed; working memory needs to be cleared and reloaded, and so on. The reason deep attention can’t happen the moment you notice something is that these things take time.
What’s more, each of these subsystems update what they are reacting to at a different rate. Your visual cortex can cohere in less than half a second. A stress hormone like cortisol, on the other hand, has a half-life of 60–90 minutes and so can take up to 6 hours to fully clear out after the onset of an acute stressor. This means that if we switch what we pay attention to more often than, say, every 30 minutes, our system will be more or less decohered—different parts will be “attending to” different aspects of reality. There will be “attention residue” floating around in our system—leftovers from earlier things we paid attention to (thoughts looping, feelings circling below consciousness, etc.), which crowd out the thing we have in front of us right now, making it less vivid.
AI
Cutting-Edge AI Was Supposed to Get Cheaper. It’s More Expensive Than Ever.
Wsj • Christopher Mims • August 29, 2025
AI•Tech•InferenceCosts

Overview
The article argues that building on top of today’s most capable AI models is getting pricier, not cheaper, especially for startups and small developers that rely on API access from large providers. As models “think” more—doing deeper reasoning, calling external tools, and processing longer prompts and outputs—the compute and token usage behind each user request expands. That extra “thinking” translates directly into higher, less predictable costs for companies that don’t control the underlying infrastructure but must absorb or pass on per-call fees to customers. The result is a growing squeeze on margins and business models for AI-first apps and services that had expected declining costs over time but are now encountering the opposite dynamic. The piece frames this as a structural shift: cutting-edge capability now often implies more computational work per task, which small players pay for by the request.
What’s Driving Costs Up
More tokens per interaction: Richer prompts, longer context windows, and verbose outputs increase token counts and therefore bills.
Deeper reasoning steps: Models increasingly perform multi-step “reasoning” or tool use behind the scenes; each step consumes compute, so more “thinking” can mean multiple model calls per task.
Chaining and orchestration: Complex workflows (retrieval, planning, code execution, and verification) require several sequential model invocations, compounding per-request cost.
Latency and reliability targets: To deliver fast, consistent responses, startups may pay for higher-tier services or additional capacity headroom.
The Startup Pinch
Unpredictable cost of goods sold: Per-token and per-call pricing turns usage spikes into budget shocks, complicating pricing plans and unit economics.
Product constraints: Teams redesign features to cap cost—shorter prompts, stricter output limits, or fewer automated steps—sometimes at the expense of quality.
Monetization challenges: Consumer apps hit paywalls quickly; enterprise sellers push higher-priced tiers to cover COGS, narrowing addressable markets.
Competitive disadvantage: Companies without GPU access or favorable platform terms face higher marginal costs than incumbents with scale or in-house models.
Operational Responses
Model routing: Direct simple tasks to smaller, cheaper models while reserving premium models for high-stakes queries.
Prompt and context hygiene: Aggressively trim context, deduplicate retrieved documents, and compress histories to reduce tokens.
Tooling discipline: Limit unnecessary tool calls and “reasoning depth”; set compute budgets that bound internal steps per request.
Caching and reuse: Store frequent responses, intermediate results, and embeddings to avoid repeated computation.
Specialized models: Fine-tune compact models for specific domains, trading some peak performance for predictable, lower-cost inference.
Strategic Implications
Platform power consolidates: As costs rise with capability, the providers who control the best models and hardware capture more value, increasing dependence for downstream developers.
Differentiation shifts: Durable advantage moves from generic “we added AI” features to proprietary data, workflows, and integrations that justify higher prices and reduce wasteful calls.
Efficiency becomes a moat: Startups that bake cost-awareness into architecture—budgeted reasoning, partial on-device inference, smart retrieval—gain resilience.
Market segmentation: Premium, high-reasoning experiences cluster in enterprise or mission-critical use cases; consumer offerings gravitate toward smaller models or constrained features.
Key Takeaways
“With models ‘thinking’ more than ever,” each user interaction can trigger extra compute and multiple API calls, raising per-request costs.
Startups relying on third-party AI face margin pressure, pricing complexity, and design trade-offs that challenge scale.
Cost control now sits alongside accuracy and latency as a core product requirement; architecture and process choices materially impact unit economics.
The near-term arc favors companies with efficiency tooling, proprietary data advantages, or hybrid stacks that minimize expensive calls without degrading outcomes.
Elon Musk Just Delivered a Ringing Endorsement of the iPhone’s Staying Power
Wsj • August 31, 2025
AI•Tech•Apple

Overview
“The billionaire’s lawsuit against the tech giant shows the iPhone still holds sway in AI’s future.” That core claim frames the dispute not just as a legal fight, but as a signal of where power resides in consumer artificial intelligence: with the platform that owns the hardware, default settings, and distribution. The piece argues that the iPhone, as the most influential mobile gateway for apps and assistants, remains the decisive chokepoint for how AI reaches everyday users, and that high‑profile legal pressure underscores this leverage rather than diminishes it.
Why a lawsuit highlights iPhone’s leverage
A legal challenge aimed at shaping how AI integrates with the iPhone implicitly acknowledges Apple’s gatekeeping role. Control over system defaults (which assistant wakes with a button press or wake word), on‑device permissions (microphone, camera, notifications), and App Store policy (what is allowed to run natively or as an extension) determines which AI experiences achieve mass adoption. By contesting these levers through the courts, a billionaire founder is, in effect, validating that the path to AI ubiquity still runs through iOS.
Distribution > model quality
The article positions distribution as the scarce resource. The best model or chatbot can lose if it cannot be the default experience on the device people carry most often. Placement on the iPhone home screen, deep OS hooks, and seamless hand‑offs across services can outweigh incremental model performance. The lawsuit thus reads as a play to influence distribution terms—either by forcing fairer access to defaults or by deterring platform moves that could entrench a rival assistant.
On‑device AI and privacy optics
Another theme is on‑device processing. The iPhone’s emphasis on running key tasks locally—paired with hardware optimized for machine learning—lets Apple argue for privacy‑preserving AI experiences. Any suit contesting how third‑party AI plugs into that architecture must contend with a narrative that ties device control to user trust and safety. That dynamic raises the bar for challengers: they must show both superior capability and trustworthy integration to gain iPhone‑level distribution.
Implications for developers and rivals
Developers: Expect continued pressure to align with platform policies and entitlements that govern background processing, data access, and API usage for AI features. Compliance may become the cost of reaching the iPhone’s audience.
Rivals: If you can’t win the default, you must win through standout utility in niche workflows, enterprise channels, or cross‑platform network effects. Legal routes may nudge policies at the margins but won’t replace the need for product‑led pull.
Consumers: Competition could yield better assistants, but short‑term frictions—permission prompts, switching costs, fragmented experiences—are likely as stakeholders battle for the primary interface slot on the iPhone.
Strategic read‑through
The conflict is a referendum on who sets the rules for the AI era: model makers or mobile platform owners. By centering the iPhone, the article suggests the latter still command decisive advantage. Litigation, then, becomes both tactic and testimony—an acknowledgment that shaping iPhone integration terms may matter more than marginal gains in AI accuracy. Until distribution unbundles from the device, the iPhone’s gravitational pull will continue to define which AI agents become everyday habits.
Key takeaways:
The lawsuit is less about damages and more about access to the iPhone’s distribution levers.
Defaults, OS‑level hooks, and App Store rules determine AI adoption speed.
On‑device processing and privacy positioning reinforce Apple’s control narrative.
Competitors must pair legal strategies with product differentiation and alternative channels.
Made by Google 2025, AI Trade-offs, Google and the Long-Term
Stratechery • Ben Thompson • September 2, 2025
AI•Tech•Pixel
Good morning,
Recently on Sharp Tech, Andrew and I covered Nvidia and China, the U.S. taking a stake in Intel, and K‑Pop Demon Hunters.
Made by Google 2025
Two weeks ago, Bloomberg reported Google’s newest slate of consumer hardware: a Pixel 10 lineup (standard, Pro, Pro XL, and Pro Fold) ranging from $800 to $1,800, a Pixel Watch 4 at $350–$400, and budget Pixel Buds 2a at $130. The pitch centered on deeper Gemini integration, complete with playful teases at Apple and an “ask more of your phone” tagline.
Apple’s September event is imminent and usually a glossy 90‑minute commercial; that predictability is why Google’s show felt worth writing about: it was something new.
As The Verge noted, the keynote resembled a Tonight Show taping. Jimmy Fallon hosted; Rick Osterloh did a sit‑down “interview” instead of pacing a stage; pre‑taped segments rolled between live bits. Afterward, Fallon and Googlers moved set‑to‑set in a QVC‑style tour of Pixel 10, Pixel Watch 4, and Buds 2a. Cameos and influencers showcased Gemini features; a Jonas brother premiered a “Shot on Pixel 10 Pro” video; Lando Norris and Giannis Antetokounmpo crossed sports with Gemini coaching.
Some called it cringe; I liked the novelty. More importantly, it worked: last year’s Made by Google drew about 1.3 million YouTube views, while 2025 has already surpassed 8 million—Google boosted reach by borrowing celebrity. Still, the gap remains: Apple’s 2024 iPhone event and Samsung’s July 2025 Unpacked each sit around 27 million. For them, the phones are the stars; Google hired them.
The Gross Margin Debate in AI
Tanayj • September 2, 2025
AI•Tech•GrossMargins•InferenceCosts•PricingModels
Overview
The piece maps where gross margins sit across the AI stack in 2025 and offers pragmatic guidance for application builders. It argues that while chip and cloud vendors are monetizing AI demand with healthy economics, margin pressure is most acute at the application layer, especially for coding assistants where users perceive quality on every keystroke. The author’s through line: optimize model choice and workflow control, diversify revenue beyond tokens, iterate pricing, and remember that net margin (not just gross) ultimately determines business quality.
Where margins sit today
Chips: Nvidia continues to capture premium economics, with gross margins around 70% after excluding one‑offs.
Cloud: Hyperscalers don’t break out AI product gross margin, but reported figures imply healthy profitability with some AI drag. AWS posted roughly 33% operating margin for the quarter (36.7% TTM). Microsoft said Microsoft Cloud gross margin is 69% and explicitly noted AI infrastructure is pressuring the percentage. Google Cloud delivered ≈21% operating margin. Net: platforms monetize AI while funding the buildout; estimated gross margins are in the ~50–55% range for AI services at some providers.
Models: Outside estimates put OpenAI’s gross margin near ~50% and Anthropic around ~60%, with a mix of consumer and API lines. Training costs are not included in these gross margin figures.
Applications: The widest dispersion. Bessemer’s 2025 dataset shows fast‑ramping “Supernovas” averaging ~25% gross margin early (many even negative), while steadier “Shooting Stars” trend closer to ~60%. Methods of gross margin calculation vary (e.g., whether free users’ costs are included), complicating comparisons.
Why application margins vary
Inference cost curves vs. model choice: For a given model, inference costs may fall 80–90% annually, but top‑end model prices have stayed flat or risen (as Ethan Ding’s analysis notes). The pivotal question: must you use the frontier model on every request, or simply meet a quality bar? If the latter, routing most traffic to cheaper models and bursting to frontier only when needed preserves margin; if the former, customer expectations will compress margins unless pricing mirrors usage.
Control and workflow depth: When customers demand the best model always, your COGS ride someone else’s price card. Fixed workflows (e.g., document processing, IVR) allow vendors to own acceptance criteria, default to cheaper models, and escalate only on hard cases. Depth matters: collaboration, versioning, audit, analytics, governance, and integrations push you beyond “a wrapper over a model,” improve ACVs, and nudge app‑layer margins toward SaaS‑like territory.
“Do not live or die on tokens alone”
Hosting and deploy: Platforms like Bolt and Replit monetize runtime, bandwidth, storage, domains, and private deployments once projects live in their environments—raising ARPU and decoupling margin from token pricing.
Marketplaces and services: Replit’s Bounties take a 10% fee—clean non‑inference revenue.
Advertising and affiliate: OpenAI has piloted checkout inside ChatGPT with Shopify, creating potential commission revenue on free tiers; Perplexity has tested sponsored follow‑up questions. Expect more ad formats to reach consumer chatbots over time.
Pricing model iteration as a margin lever
Teams are moving beyond simple per‑seat plans due to power‑user cost spikes. Emerging patterns include seat plus pooled credits, usage with included allowance and clear pass‑through, token bundles with rollover, and BYOK for heavy cohorts.
Replit has iterated across these ideas and saw gross margins swing meaningfully even as revenue grew. Anthropic disclosed that under an earlier Claude Code pricing structure, a $200 plan could lose “tens of thousands of dollars per month” for some power users—underscoring the need for pricing aligned to cost drivers.
Net margins, not just gross
Emphasizing gross margin alone misses the strategic trade: some teams accept thinner early gross margins for product‑led distribution and faster scale, lowering S&M and even G&A as a percentage of revenue.
Bessemer’s “Supernova” pattern captures this: very high ARR per employee, initially thin margins that thicken with routing, workflow depth, and pricing improvements. “The goal is not a perfect gross margin in isolation. The target is a healthy net margin profile as cohorts mature.”
Key takeaways for builders
Route intelligently: meet a quality bar with tiered models; burst to frontier only when necessary.
Own the workflow: deepen control, acceptance criteria, and integrations to shift from “access to a model” to durable SaaS economics.
Diversify revenue: monetize hosting/deploy, marketplaces, and ads/affiliate to decouple from inference COGS.
Fix pricing: combine seats with credits, pass‑through heavy usage, offer bundles/BYOK, and continuously tune tiers for power users.
Optimize for net margin: trade selective gross margin for distribution where it accelerates growth and improves overall unit economics over time.
OpenAI acquires product testing startup Statsig and shakes up its leadership team
Techcrunch • September 2, 2025
AI•Data•OpenAI•Statsig•Leadership
What happened
OpenAI is bringing the founder of product testing startup Statsig into the company as its CTO of Applications and is making additional changes across its leadership ranks. Alongside the personnel shift, OpenAI is moving to embed experimentation and product analytics capabilities more deeply into how it designs, builds, and scales its application-layer experiences. The appointment signals a tighter integration between cutting-edge model research and the practical, metrics-driven craft of shipping products that perform reliably for consumers and enterprises alike.
Why this matters
Statsig’s core competency is rigorous product experimentation—A/B testing, feature flagging, rollout control, and trustworthy metrics. Bringing that mindset and toolkit into OpenAI’s leadership suggests a stronger commitment to rapid iteration grounded in measurable outcomes.
A dedicated “CTO of Applications” role clarifies accountability for the app layer (for example, consumer- and enterprise-facing interfaces and workflows) distinct from foundational model research and infrastructure. That separation can accelerate decision-making while improving quality, safety checks, and shipping velocity.
Leadership adjustments often precede product roadmap shifts. Expect tighter feedback loops between usage data, experimentation results, and feature prioritization, with expansion of observability and reliability practices inside OpenAI’s app stack.
What the CTO of Applications is likely to drive
Execution at the interface between advanced models and end-user value: translating model capabilities into durable features, workflows, and APIs that solve concrete user problems.
A unified experimentation framework so teams test consistently, compare apples-to-apples metrics, and avoid “metric drift.” This includes disciplined guardrails for rollouts, canaries, and reversions when features underperform.
Better “product fitness functions” that combine quantitative signals (engagement, latency, cost-to-serve, error rates) with qualitative feedback loops (UX research, enterprise requirements), enabling faster, safer iteration.
Stronger alignment with trust and safety: building pre-deployment checks and post-deployment monitoring directly into the product pipeline, so risk assessment happens continuously rather than episodically.
Implications for users and developers
Users should see more frequent, controlled improvements in application features, accompanied by clearer changelogs and faster fixes when regressions occur.
Enterprises may benefit from more predictable performance and governance features—versioning, auditability of changes, and opt-in controls during feature rollouts—reflecting experimentation best practices adapted to regulated environments.
Developers could get richer telemetry and evaluation tools around the application layer, making it easier to diagnose model- vs. product-level issues, measure business impact, and optimize prompts or fine-tuning strategies within product workflows.
Organizational and market context
The leadership shake-up concentrates product authority and makes experimentation a first-class function. That tends to reduce handoffs, shorten cycle time from idea to live test, and institutionalize “evidence over intuition.”
In a competitive AI market, the differentiator is increasingly the application experience—latency, reliability, cost control, and task completion rates—rather than raw model specs alone. Elevating an applications-focused CTO reflects that reality and could pressure rivals to tighten their own experimentation pipelines.
For the broader ecosystem, deeper in-house experimentation at OpenAI may reduce reliance on external testing tools for its flagship products, while raising the bar for what customers expect from AI application quality and transparency.
Key takeaways
OpenAI is adding the founder of a product experimentation startup as CTO of Applications and reshaping other leadership roles to emphasize measurable product excellence.
Expect faster, data-driven iteration across consumer and enterprise apps, with consistent A/B testing, feature flagging, and rollout controls built into the development lifecycle.
The move signals that the application layer—not just model breakthroughs—will be central to OpenAI’s next phase of differentiation, with stronger ties between safety, reliability, and product performance.
Users, enterprises, and developers should anticipate clearer metrics, improved stability, and more deliberate governance in how features are released and evaluated.
🔮 Could AI offset baby boomers retiring?
Exponentialview • September 3, 2025
AI•Work•Productivity
Overview
The piece argues that two powerful forces—ageing demographics and accelerating AI—are set to counterbalance one another in the United States over the next decade. With a record number of Americans turning 65 in 2025 and roughly 16 million expected to retire by 2035, the shrinking worker-to-retiree ratio threatens growth, strains Social Security, and elevates healthcare demand. Yet, drawing on long-run data and a structured forecasting approach, the author contends that AI-enabled productivity could offset much of this demographic drag. “Most American workers will feel AI’s impact – but not as a replacement,” the essay stresses, positioning technology as a productivity catalyst rather than a job destroyer.
How AI could offset the “silver tsunami”
The argument hinges on task-level, not job-level, analysis. Examining more than 800 U.S. occupations, the research finds that about four in five roles are likely to see a blend of automation and augmentation, yielding roughly 43% time savings on current task bundles. Only about 16% of jobs—those with highly repeatable tasks and 40%+ automatable time—face significant displacement risk. Examples span from routine office tasks (scheduling, data entry, project coordination) to portions of programming work. Crucially, the freed capacity can be reallocated to higher-value, human-centric tasks, lifting service quality and overall output—akin to “boomers never retiring” in macroeconomic effect.
Model, data, and scenarios
Underpinning these conclusions is the Vanguard Megatrends Model, a forward-looking framework that integrates technology, demographics, globalization, and fiscal debt. The model’s engine is a vector autoregression tracking 15 indicators (e.g., real GDP, inflation, rates, labor force participation, equity valuations) over 130 years and billions of historical data points. From this, two main scenarios emerge for the 2030s:
Productivity Surges (45–55% probability): AI matures into a general-purpose technology—like electricity—beating the productivity impact of the PC and the internet by the early 2030s, enabling near 3% U.S. real GDP growth, the fastest since the late 1990s. Stronger growth helps restrain inflation and narrows deficits via higher tax receipts.
Deficits Drag (30–40% probability): AI underdelivers while public deficits keep climbing. Higher interest and borrowing costs slow credit formation; inflation proves sticky; homeownership erodes; U.S. growth converges toward a lower European-style pace. Monetary policy provides limited relief; the key lever remains how organizations deploy technology to raise productivity.
Impacts on occupations and skills
The essay emphasizes evolution over elimination of jobs. In healthcare, for instance, AI transcription and NLP can shift nurses’ time from EHR data entry to patient care. In education, HR, and pharmacy, augmentation enhances service quality and throughput. Programmers may be displaced from certain coding and testing tasks (roughly 45% of their day), but many can transition into AI-oriented roles due to task overlap across computing occupations. The durable skills set is distinctly human: critical thinking, creativity, emotional intelligence, and complex problem-solving—especially in people-facing sectors (healthcare, education, social work). While STEM wage premia may compress, analytical and tech fluency remain valuable for integrating AI into workflows.
Policy and organizational responses
Past transitions caution against neglecting workers. Policymakers can reduce frictions by pruning unnecessary credentialing, easing occupational licensing, and widening access to affordable reskilling pathways. Employers, learning from the post-COVID recovery, can broaden hiring pipelines and recognize skill portability rather than privileging narrow credentials. The goal is to accelerate mobility from automating roles into augmented ones, shortening income disruptions and preserving community tax bases.
Investor implications
For savers and asset allocators, the essay advises acting on probabilities rather than hype. If AI proves general-purpose, benefits will radiate beyond the “Magnificent Seven” to downstream adopters and newly created industries. Given the uncertainty across the two scenarios, broad diversification and a long-term horizon remain first principles. Portfolio design should be resilient to both an AI-led productivity boom and a deficits-led drag, with capacity to adapt as realized productivity signals and fiscal dynamics unfold.
• Key takeaways
AI’s impact will be pervasive but primarily augmentative; displacement is concentrated in about 16% of jobs with high automatable task shares.
Average task-level time savings around 43% can meaningfully boost output and quality without wholesale job loss.
Near-3% U.S. GDP growth in the 2030s is plausible under a productivity surge, potentially the strongest since the late 1990s.
A deficits-drag path remains a sizable risk; monetary policy alone cannot solve productivity shortfalls.
Policy should target mobility: reduce credential barriers, expand reskilling; employers should hire for skills, not just pedigrees.
For workers, human-centric competencies—critical thinking, creativity, EQ, complex problem-solving—are the safest against automation.
For investors, diversify beyond headline AI leaders and position for broad-based productivity diffusion while hedging fiscal and rate risks.
Context is Important, Metadata Provides It
Medium • ODSC - Open Data Science • September 3, 2025
AI•Data•ModelContextProtocol
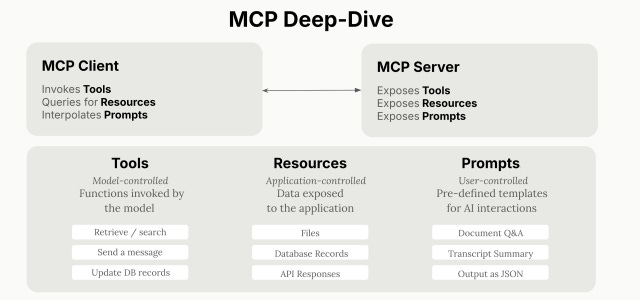
Why Context Is the Missing Ingredient in AI Workflows
The article argues that many failures in data science and AI—flawed assumptions by practitioners, misleading recommendations from agents, and superficially plausible LLM outputs—stem from a lack of organizational context. Even intelligent systems with ample raw data falter when they cannot access the right business-specific information, relationships, and permissions. The core claim is that context must be both accessible and structurally coherent for AI to make reliable, auditable decisions. As the author puts it, “context alone isn’t good enough”; it must be unified and governed to be useful across teams and use cases.
Enter Model Context Protocol (MCP)
MCP, open-sourced by Anthropic, standardizes how AI systems integrate with tools and data sources. Instead of building custom connectors for every application, organizations can implement a single MCP server per system that exposes functionality with consistent patterns for authentication, data exchange, and function calling. This simplifies the “last-mile” integration problem and lets AI agents reliably discover and invoke capabilities across a heterogeneous stack. With MCP, an LLM can request not just data, but actions—invoking functions in external applications with predictable inputs/outputs—thereby closing the loop between insight and execution.
Why MCP Alone Doesn’t Solve Context
An MCP connection pipes information, but it does not guarantee the information is complete, consistent, or permission-appropriate. The article illustrates this with a sales churn example: a CRM exposed via MCP might list accounts but omit critical product usage signals, include hundreds of duplicate records, or expose data beyond a rep’s access rights. Scaling by adding more MCP servers can quickly become unmanageable as use cases, users, and tools proliferate. Without consolidation, AI remains prone to hallucination, bias, and brittle workflows because it still lacks a single, authoritative view of the business domain.
Metadata Platforms as the Context Backbone
Metadata platforms provide that unifying layer. They ingest and model complete data context—datasets, schemas, ownership, usage patterns, upstream/downstream lineage, quality tests, dashboards, and ML assets—into a coherent knowledge graph. This “Unified Knowledge Graph” supports discovery, quality, lineage, observability, and governance in one place, serving as a durable source of truth “across all your data systems across all departments across all time.” When exposed through MCP servers, the metadata layer becomes both readable (for retrieval and analysis) and writable (so agents can propose or make governed updates), enabling organizationally aware assistants that reason with policy-aware, end-to-end context.
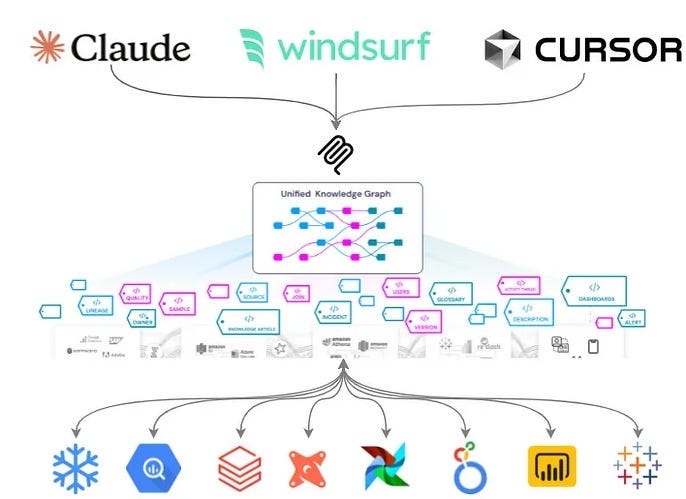
OpenMetadata + MCP + Goose: A Practical Stack
The article highlights OpenMetadata as an open-source unified metadata platform that auto-discovers and catalogs data across the stack, tracks real-time lineage, and enforces governance at scale. Its MCP server exposes the knowledge graph to AI agents, turning generic LLMs into context-rich assistants informed by business semantics and access controls. The piece also mentions Goose, an extensible open-source AI agent, as part of a hands-on tutorial demonstrating how to wire these components together so prompts, tools, and governance remain fully open-source and extensible.
Implications for Teams
Lower integration overhead: MCP reduces bespoke connectors; a single server per tool scales across agents.
Reduced hallucinations and safer automation: The metadata graph narrows the context window to authoritative, permissioned data and captures lineage and quality signals.
Faster time-to-value: Reusing the same governed context across analytics, ML, and agents allows consistent answers and actions.
Continuous improvement loop: Agents can read from and (governed) write back to the knowledge graph, improving documentation, ownership metadata, and lineage over time.
What You’ll Learn in the Tutorial
Foundations: OpenMetadata, MCP servers, and Goose, and how they reshape the modern data/AI stack.
Use cases: Churn risk, discovery and lineage-aware analytics, policy-aware data access, and metadata-driven observability.
Build experience: Stand up an open-source system you can extend to your own environment and “prompt completely in open-source,” ensuring transparency and portability.
Key Takeaways
MCP standardizes tool integration for AI, but sustainable accuracy demands a unified, governed context layer.
Metadata platforms supply that backbone via a Unified Knowledge Graph encompassing discovery, lineage, quality, observability, and governance.
OpenMetadata’s MCP server operationalizes this vision, enabling agents to act with business-aware, permissioned knowledge—turning LLMs from generic chatbots into trustworthy collaborators.
Mistral Set for $14 Billion Valuation With New Funding Round
Bloomberg • September 3, 2025
AI•Funding•MistralAI

Overview
A French artificial intelligence startup is finalizing a landmark fundraising that underscores the accelerating competition in the AI sector. According to the article, Mistral AI is set to secure approximately €2 billion in new capital, establishing a €12 billion valuation (about $14 billion) that includes the fresh funding. The article characterizes this round as one that “solidif[ies] its position as one of Europe’s most valuable tech startups,” reflecting both investor confidence and the strategic importance of next-generation AI models in the global technology landscape.
Key Numbers and Structure
Investment size: €2 billion (new capital being finalized).
Implied valuation: €12 billion total, inclusive of the new round (roughly $14 billion).
Competitive status: The valuation places the company among Europe’s most valuable startups, highlighting its prominence in the regional tech ecosystem.
Currency note: The article provides both euro and dollar figures, signaling international investor interest and relevance.
What This Signals About the AI Market
This capital raise illustrates the scale of funding now required to compete at the frontier of AI, where training state-of-the-art models and serving them at scale demands substantial spending on compute, talent, and data. A €12 billion valuation suggests expectations that the company will translate technical progress into commercial traction—through enterprise tooling, model access, or partnerships—while also keeping pace with rapid advances in model capability and efficiency. In practical terms, rounds of this magnitude often support multi-year compute commitments, accelerated hiring for research and engineering teams, and expansion of go-to-market efforts across priority sectors such as software, cloud, and industrial applications.
Strategic Positioning and Competitive Implications
European leadership: The raise reinforces Europe’s capacity to nurture globally relevant AI champions, potentially narrowing gaps with US-based peers.
Capital intensity: The size of the round signals a willingness among investors to fund long-term platform bets, not just application-layer startups.
Ecosystem effects: A flagship raise can catalyze local supplier networks (cloud, semiconductors, MLOps) and attract experienced operators and researchers to the region.
Risks and Execution Challenges
While the valuation underscores strong momentum, it also raises execution thresholds. To justify a €12 billion price tag, the company will need to demonstrate defensibility—via model quality, speed of iteration, reliability, and cost-performance—and translate technical lead into recurring revenue. Key risks include rising inference costs, talent competition, regulatory shifts in AI safety and data governance, and the possibility of model commoditization if open ecosystems advance quickly. The ability to differentiate on safety, customization, and domain performance will be pivotal to converting interest into durable enterprise contracts.
Why the Valuation Matters
Valuation here functions as a signal of expected market share and future cash flows in a rapidly expanding category. It also sets a benchmark for European AI startups seeking large-scale financing and may influence how sovereign funds, corporate strategics, and global venture investors allocate capital across regions. The inclusion of both euro and dollar figures suggests cross-border relevance and could ease future partnerships with multinational customers or infrastructure providers.
What to Watch Next
Deployment of proceeds: Expect prioritization of compute capacity, model R&D, and commercialization.
Product footprint: Movement from research milestones to enterprise solutions and developer tools.
Regional impact: Potential knock-on effects for European AI policy discussions and funding appetites.
Competitive response: How peers adjust pricing, release cycles, and partnership strategies in light of this raise.
Key Takeaways
“€2 billion investment” and “€12 billion ($14 billion)” valuation underscore the capital intensity and momentum in frontier AI.
The company is positioned as one of Europe’s most valuable startups, elevating the region’s profile in the global AI race.
Execution against compute scaling, productization, and go-to-market will determine whether the valuation converts into durable leadership.
How ‘neural fingerprinting’ could analyse our minds
Ft • September 4, 2025
AI•Tech•NeuralFingerprinting•Magnetoencephalography•Neuroprivacy
Scientists are exploring “neural fingerprinting” — the idea that patterns of brain activity are distinctive enough to identify individuals and reveal how their minds work. Recent advances in wearable magnetoencephalography are accelerating this shift. Lightweight helmets that use optically pumped magnetometers can capture minute magnetic fields produced by neurons without the bulky, cryogenically cooled systems of older MEG machines. Because they are portable and non‑invasive, these devices allow people to move naturally while their brain activity is recorded, offering a richer, more realistic picture of cognition.
Unlike structural imaging, which shows what the brain looks like, neural fingerprints are functional: they map how networks communicate in real time. Researchers say such signatures could help pinpoint abnormalities linked to conditions including schizophrenia, epilepsy and dementia, potentially enabling earlier detection and more personalised treatment. Combining these measurements with machine‑learning techniques may also help track how a patient responds to therapy, or predict who is at higher risk before symptoms become debilitating.
The technology is advancing beyond laboratories. Academic groups in Europe and North America have begun testing wearable MEG systems in clinical studies, and developers are preparing for regulatory pathways. The promise is to move from static snapshots to continuous, precise monitoring of brain dynamics — at rest, during tasks, and even in everyday environments — to build robust, individualised profiles.
With new capability comes risk. If neural fingerprints are linked to traits shaped by upbringing or socio‑economic background, they could be misused for cognitive profiling. Brain data are uniquely sensitive, difficult to anonymise and, once collected, hard to retract. Ethicists argue for stringent data‑protection rules, clear consent standards and recognition of “cognitive liberty” — the right to keep one’s thoughts from being probed or manipulated.
Parallel progress in brain‑computer interfaces underscores the stakes. Non‑invasive EEG systems paired with AI are helping some paralysed patients control cursors and type, while invasive implants promise higher‑bandwidth links from companies such as Neuralink and state‑backed efforts in China. As commercial interest grows, safeguards around data ownership, security and permissible use will determine whether neural fingerprinting becomes a clinical breakthrough or a new avenue for surveillance.
GPT-5: The Case of the Missing Agent
Secondthoughts • September 4, 2025
AI•Tech•GPT
Welcome to the 1800 new readers (!) who joined since our last post, “35 Thoughts About AGI and 1 About GPT-5”. Here at Second Thoughts, we let everyone else rush out the hot takes, while we slow down and look for the deeper meaning behind developments in AI. Welcome aboard!
AI has made enormous progress in the last 16 months. Agentic AI seems farther off than ever.
Back in April 2024, there were rumors that OpenAI might soon be releasing GPT-5. At the time, I took the opportunity to share some predictions, in which I suggested that the key question was whether it would “represent meaningful progress toward agentic AI”.
16 months later, OpenAI has finally decided to apply the name GPT-5 to a new model. And while it’s quite a good model, I find myself thinking that truly agentic AI seems farther off today than it did back then. All of the buzz about “research agents”, “coding agents”, and “computer-use agents” has distracted us from the original concept of agentic AI.
What Is Agentic AI?
Today, we have coding agents that can tackle moderately sized software engineering tasks, and computer use agents that can go onto the web and book a flight (though not yet very reliably). But the full vision is much more expansive: a system that can operate independently in the real world, flexibly pursuing long-term goals.
Shortly after the release of GPT-4, developer Toran Bruce Richards created an early attempt at a general-purpose agentic AI, AutoGPT. As Wikipedia explains, “Richards's goal was to create a model that could respond to real-time feedback and pursue objectives with a long-term outlook without needing constant human intervention.”
The idea was that you could give AutoGPT a goal, ranging from writing an email to building a business, and it would pursue that mission by asking GPT-4 how to get started, and then what to do next, and next, and next. However, this really didn’t work well at all – it would create overly complex plans, get stuck in loops where it kept trying the same unsuccessful action over and over again, lose track of what it was doing, and generally fail to accomplish anything but the most straightforward tasks. Perhaps that was for the best, given that inevitably some joker renamed it “ChaosGPT”, instructed it to act as a “destructive, power-hungry, manipulative AI”, and it immediately decided to pursue the goal of destroying humanity. (Unsuccessfully.)
There’s been a lot of progress since GPT-4. Beginning with OpenAI’s o1, “reasoning models” receive special training to carry out extended tasks, such as writing code, solving a tricky math problem, or researching a report. As a result, they’re able to sustain an extended train of thought while working on a task, making relatively few errors, and often correcting any errors they do make. This is supported by a dramatic increase in the size of “context windows” (the amount of information an LLM can keep in mind at one time). The original GPT-4 supported a maximum of 32,000 tokens (roughly 25,000 words); in April 2024, GPT-4 Turbo offered 128,000 tokens; as of this writing, GPT-5 goes up to 400,000 tokens. Meanwhile, back in February 2024, Google announced Gemini 1.5 with a 1M token window.
With all the progress over the last 16 months, are AI agents ready to deal with the real world?
OpenAI set to start mass production of its own AI chips with Broadcom
Ft • September 4, 2025
AI•Tech•OpenAI
OpenAI is preparing to begin mass production of a custom AI accelerator co‑designed with Broadcom, marking a significant move to secure dedicated compute for its models and lessen reliance on Nvidia’s GPUs. The effort reflects a wider shift among leading tech companies to build tailored chips for AI workloads as demand for training and inference capacity accelerates.
The in‑house processor, described internally as an “XPU,” is intended for OpenAI’s own use rather than external sale. By controlling key elements of the hardware stack, the company aims to improve performance per dollar and per watt, stabilize supply, and better match silicon features to its evolving model architectures.
OpenAI’s collaboration with Broadcom began last year and elevates the AI group into the select roster of hyperscale customers for Broadcom’s custom accelerator business. Manufacturing is expected to be handled by TSMC on an advanced process, with initial production targeted as early as next year. The partnership is also notable in the context of Broadcom’s expanding AI revenue base, which has been buoyed by substantial orders for bespoke accelerators.
The move aligns OpenAI with peers including Google, Amazon and Meta, each of which has developed proprietary silicon to reduce costs, mitigate supply constraints and optimize for specific AI tasks. While OpenAI continues to run large fleets of Nvidia hardware and has incorporated AMD chips, its custom device is designed to complement that mix and support the next generation of models, including successors to GPT‑4‑class systems. Together, these steps underscore how competition for cutting‑edge AI capability is reshaping the semiconductor landscape, as leading AI developers seek more control over their compute destiny.
Media
Cloudflare’s CEO wants to save the web from AI’s oligarchs. Here’s why his plan isn’t crazy.
Crazystupidtech • Fred Vogelstein • August 30, 2025
Media•Journalism•Cloudflare•PayPerCrawl•AIChatbots
Sixteen years ago Matthew Prince and classmate Michelle Zatlyn at Harvard Business School decided there was a better way to help companies handle hacker attacks to their websites. Prince and a friend had already built an open source system to help anyone with a website more easily track spammers. What if the three of them could leverage that into a company that not only tracked all internet threats but stopped them too?
Within months they had a business plan, won a prestigious Harvard Business School competition with it, and had seed funding. They unveiled the company, Cloudflare, a year later at the 2010 Techcrunch Disrupt competion, taking second place. And today, riding the explosion of cloud computing and armed with better technology and marketing, they’ve leapfrogged competitors to become one of the dominant cybersecurity/content delivery networks in the world.
It’s one of the great startup success stories out of Silicon Valley in the past decade. Cloudflare went public in 2019 and is now worth roughly $70 billion. That makes it about number 400 on Yahoo’s list of companies by market cap, making it about as big as Marriott, Softbank and UPS. And it’s turned Prince, 50, into a certified tech oligarch worth $6 billion.
But today, in the middle of August, Prince isn’t on a video feed in front of me because he wants to talk about any of that. He wants to talk about saving something old, not building something new. He wants to talk about saving the World Wide Web and all the online journalism it has spawned.
I’ve never had a conversation with a big tech CEO like this, and I’ve interviewed a lot of them. The best are super high energy, inspiring, out-of-the-box thinkers. But “save,” “old,” “journalism,” and “liberal arts” are dirty words to many of them, especially when they make it big. Some I know would put big screen TVs where the paintings are in the Louvre.
But Prince isn’t like most entrepreneurs I’ve met, either. He’s more of a Renaissance man in geek clothing. Sure he studied computer science at Trinity College in Hartford. But he was also a ski bum, who edited the school newspaper. And he only minored in computer science. His actual major was English.
He wrote his college thesis in 1996, two years before Google was founded, on the potential for political biases in search engines. And while he had offers to work for companies like Netscape, Yahoo and Microsoft after graduating, at that point in his life the idea of being a programmer actually sounded boring to him.
Instead, he went to law school at the University of Chicago, where he also started a legal magazine. Cloudflare grew out of Unspam Technologies, an open source project he started with Lee Holloway after law school while he was also teaching cybersecurity law at the University of Illinois.
Prince wants to talk about the future of the web and journalism with me because he thinks the AI chatbot revolution is killing both of them. And he thinks he can help fix that with something he calls pay-per-crawl, a gambit he and Cloudflare launched on July 1. He cares, he says, because “I love the smell of printer ink and a big wet press. So I kind of have a soft spot for the media industry and how important it is.” This isn’t spin. Two years ago he and his wife bought the Park City Record, his hometown local paper.
Substack Cofounder on the Internet's Content Problem
Youtube • a16z • September 2, 2025
Media•Publishing•Substack•CreatorEconomy•ContentModeration
An Interview with Cloudflare Founder and CEO Matthew Prince About Internet History and Pay-per-crawl
Stratechery • Ben Thompson • September 4, 2025
Media•Publishing•PayPerCrawl
Overview
Ben Thompson’s interview with Matthew Prince explores Cloudflare’s origin story, the company’s opportunistic product strategy, and why Prince is pushing “pay‑per‑crawl” to reset the web’s broken value exchange in the age of AI answer engines. Prince argues that the interface of the internet has shifted from search to AI-generated answers, severing the old quid pro quo in which Google sent traffic in exchange for free crawling; without a new compensation model, quality journalism and unique knowledge production will wither or be captured by a few powerful patrons. (stratechery.com)

Founding, architecture, and “bottoms‑up” strategy
Prince recounts a nontraditional path—English major, law school, Unspam—and the formative role of engineer Lee Holloway in building core technology that later catalyzed Cloudflare. From eight people “above a nail salon,” Cloudflare chose commodity hardware and software-defined orchestration (inspired by Google’s scale-out model) to deliver security and performance at internet scale. This common architecture let Cloudflare continuously repurpose underused capacity into new services, compounding margins and capabilities. (stratechery.com)
Cloudflare’s original aspiration—“a firewall in the cloud”—evolved through a freemium model that attracted NGOs and, inevitably, adversaries, forcing Cloudflare to harden its stack and even run a registrar to close supply‑chain gaps. The lesson: start small, solve urgent customer problems, and let the platform’s breadth emerge organically. (stratechery.com)
Why pay‑per‑crawl, and why now
Prince says the web’s 25‑year search era depended on Google sending monetizable traffic; AI “answer engines” invert that bargain by giving answers without clicks. He outlines three futures: 1) a collapse in original reporting and research, 2) a Medici‑style oligopoly of a few richly funded AI providers that underwrite content, or 3) a new market where AI companies share revenue with content creators. He favors the third and proposes a straw‑man pool funded at roughly “$1 per monthly active user per year,” or about $10 billion today—enough, he argues, to replace open‑web ad revenue outside the major walled gardens. (stratechery.com)
Prince also cites data suggesting how the traffic exchange has deteriorated: “over the last 10 years, it’s become 10x harder to get a click from Google; it’s now 750x harder with OpenAI, and 30,000x harder with Anthropic,” reinforcing the urgency to price access to content rather than rely on referrals. (stratechery.com)
How it would work (and Cloudflare’s role)
At a technical level, Cloudflare’s pay‑per‑crawl integrates with existing web standards to make access programmable: compliant crawlers present payment intent and receive content; non‑paying crawlers can be met with a “402 Payment Required” response that includes pricing; Cloudflare acts as merchant of record and provides enforcement at the edge. Prince says Cloudflare is uniquely positioned because blocking and identifying bots is its daily work—and because publishers themselves asked for help as AI scraping spiked. (stratechery.com)
He stresses scarcity as the necessary precondition for a functioning market. Examples like Reddit—whose insistence on paid access yielded a reported $120 million in 2024 licensing revenue and more in 2025—illustrate how differentiated, non‑fungible datasets command higher prices than general‑interest news text. (stratechery.com)
The Google problem, Perplexity controversy, and near‑term bets
Prince calls Google “the problem” insofar as AI Overviews are governed by the core Googlebot—making opt‑out difficult without sacrificing search presence. He predicts that, within 12 months, Google will voluntarily offer publishers a way to opt out of Overviews; if not, regulators may force it. Meanwhile, Cloudflare blocks AI model training traffic (e.g., Gemini) at scale but has not blocked search or RAG, signaling support for responsible competition. Prince also rebukes Perplexity for allegedly evading blocks and fabricating article text from ad‑tech crumbs—behavior he labels “fraud.” (stratechery.com)
Implications
If AI firms compete on unique content access rather than algorithms, expect a shift toward licensing, exclusivity, and premium pipelines of local, specialized, and community data—potentially reviving local news and niche expertise. (stratechery.com)
Enforcement and payments embedded in the HTTP layer could create a standardized “content market rail,” lowering transaction costs for both large AI platforms and small creators. (stratechery.com)
Cloudflare’s push is both mission‑aligned (a “better internet”) and self‑interested (a new edge‑native marketplace). But the decisive actor remains Google: whether it enables genuine opt‑outs and participates in a compensation framework will shape which of Prince’s three futures wins. (stratechery.com)
Key takeaways
The web’s traffic‑for‑crawl bargain has broken under AI answer engines; new compensation is needed. (stratechery.com)
Prince’s straw‑man: $1/MAU/year (~$10B) redistributed to creators; scarcity will drive pricing. (stratechery.com)
Data points: 10x harder to get a Google click in a decade; 750x (OpenAI) and 30,000x (Anthropic) worse on referrals. (stratechery.com)
Cloudflare aims to operationalize pay‑per‑crawl via web standards and edge enforcement. (stratechery.com)
Google’s policies and regulatory pressure will determine the pace and shape of the transition. (stratechery.com)
Venture
The IPO Market Is Opening Up. These 14 Companies Could Be Next.
Crunchbase • September 2, 2025
Venture
After a prolonged winter, the IPO market in 2025 has finally thawed, with companies from Chime to Figma to CoreWeave launching big debuts in the first eight months of the year. So, who’s next?
To help answer that question, we used Crunchbase’s predictive intelligence tools to curate a list of 14 venture-backed companies in sectors ranging from AI to fintech to consumer goods that could be on tap as IPO candidates in the foreseeable future. Some of them are known IPO hopefuls; others, more under-the-radar picks that nonetheless have strong credentials for a public-market launch. Let’s take a closer look.
Fintech
Stripe
There is perhaps no IPO more anticipated than that of payments giant Stripe. And, unsurprisingly, the fintech is “very likely” to go public, according to Crunchbase predictions.
However, Stripe seems to be doing so well as a private company that some people speculate it has no reason to take to the public markets. Stripe, which has dual headquarters in San Francisco and Ireland, is not only the most-valuable fintech in the world, it’s one of the most-valuable private companies, period. But instead of going public, it’s thus far been offering early investors and employees liquidity through secondary sales. In February, for example, Stripe announced a tender offer in which investors would buy up shares from current and former employees at a valuation of $91.5 billion. Stripe passed the $1.4 trillion total payment volume threshold in 2024. Says F-Prime: “There are no perfectly reliable sources for Stripe’s revenue, but some sources estimate they surpassed $16B in 2023.”
Since its 2010 inception, Stripe has raised more than $9 billion in funding from investors such as General Catalyst, Y Combinator, Andreessen Horowitz, Sequoia Capital and Khosla Ventures. Whether it finally decides to take the plunge into the public markets remains to be seen, but if it does, there is no doubt its filing will be devoured by media and fintech enthusiasts alike.
Airwallex
Airwallex, a Singapore-based global payments and financial platform, is also “very likely” to go public, per Crunchbase predictions. CEO Jack Zhang has stated that the plan is to have Airwallex make its public market debut by the end of 2026, although the company is reportedly “not in a rush” to list. Interestingly, Airwallex rejected a $1.2 billion acquisition offer from Stripe in 2018. And that probably wasn’t a bad move. Founded in 2015 in Melbourne, Australia, the Stripe competitor has raised more than $1.2 billion in funding and was valued at over $6.2 billion as of its last raise — a $300 million Series F in May 2025 that included $150 million in secondary share transfers. Investors include Sequoia Capital, HSG,Blackbird Ventures, Hillhouse Investment and Salesforce Ventures
, among others.
In August 2024, CNBC reported that Airwallex had reached an annual revenue run rate of $500 million after seeing major growth in its North American and European businesses. In announcing its Series F, the company projected that it was “on track to hit $1 billion in annualized revenue in 2025, as businesses of all sizes look to expand globally without friction.” That follows its achievement of $720 million in annualized revenue in March, up 90% year over year, according to the company. It touts more than 150,000 customers globally, including Bill, Bird, Brex, Deel, Rippling, Navan, Qantas and ZipHQ.
— Mary Ann Azevedo
Enterprise tech and AI
Cerebras Systems
We know that AI chip company Cerebras, founded in 2016 by Andrew Feldman, has been gearing up to go public. The Sunnyvale, California-based company filed with the SEC to go public at the end of 2024. It then delayed its offering due to regulatory scrutiny over its ties to UAE-based G42, which has since been cleared by the Committee on Foreign Investment in the United States. The company is considered a “probable” IPO candidate by Crunchbase. In its filing, Cerebras noted its dependence on a single customer, Group 42, a subsidiary of its investor G42, responsible for more than 80% of revenue in 2023 and the first half of 2024. Cerebras has built a larger chip that is 10x faster for AI training and inference compared to leading GPU solutions, according to the company. Its customers include Mistral AI, Perplexityand the Mayo Clinic. Cerebras is reported to be raising $1 billion in funding which could delay its plans to go public. Still, the market conditions are good for an AI chip company. Nvidia has topped $4 trillion in value and Astera Labs, which went public in March 2024 at $36 per share, has doubled its price from mid-July to mid-August to over $180.
Databricks
Databricks, at the center of AI and data, is a strong candidate to go public in the next year. The San Francisco-based company is one of the 10 most-valuable private companies in the world, with a reported $3 billion in revenue run rate as of Jan. 31, and on track to deliver positive free cash flow. In December, Databricks raised a $10 billion funding, the largest round in 2024, which valued it at $62 billion. The 12-year-old company has also been on a buying spree, notably purchasing AI infrastructure builder MosaicML in 2023, data management service Tabular in 2024, and sql database solution developer Neon in 2025, each at $1 billion or more. Crunchbase indicates it’s a “probable” IPO candidate.
— Gené Teare
Clay
Clay sits at the red-hot intersection of AI and marketing and is a “probable” IPO candidate, per Crunchbase predictions. Its growth metrics and scale seem to support that outlook, with the company projecting $100 million in 2025 revenue — triple its 2024 figure. It has likewise tripled its valuation in just over a year from $500 million to $3.1 billion in a $100 million Series C raise last month. The New York-based startup, founded in 2017, is reportedly nearing profitability. It’s backed by IPO-savvy investors including CapitalG, Meritech Capital Partnersand Sequoia Capital, further bolstering its public-market credentials. The company claims to have invented the “GTM (go-to-market) engineering role,” which CEO and co-founder Kareem Amin has described as “the first true AI-native profession.”
— Marlize van Romburgh
Cybersecurity
Ledger
Crypto wallet startup Ledger is “very likely” to IPO, according to Crunchbase predictions. That makes sense, as the French startup, founded in 2014, is well-positioned at the intersection of two currently hot industries: cybersecurity and blockchain. Paris-based Ledger offers a hardware wallet to secure crypto private keys. It has raised some $577 million from venture investors including Molten Ventures and Samsung Ventures, per Crunchbase. CEO Pascal Gauthier told European tech publication Sifted in June that Ledger is actively thinking about a U.S. stock market debut, likely within the next three years. It also has plans to expand beyond crypto security into cybersecurity more broadly. While he didn’t disclose revenue figures, Gauthier said Ledger has sold 8 million of its devices to date and estimated that 20% of the world’s crypto assets are protected via the company’s wallets. “Our size is compatible with an IPO,” he said. “That’s a short-medium term vision.”
Anthropic Nearly Triples Valuation To $183B With Massive New Funding
Crunchbase • Marlize van Romburgh • September 2, 2025
Venture

Generative AI company Anthropic said Tuesday that it has raised a $13 billion Series F round at a $183 billion valuation. Iconiq Capital led the round, with Fidelity Management & Research Co. and Lightspeed Venture Partners co-leading.
With the new funding, Anthropic becomes the fourth-most valuable private company in the world, per Crunchbase data. The San Francisco-based company remains the second-most highly valued generative AI startup behind rival OpenAI, which was valued at $300 billion most recently.
The announcement confirms reporting over the summer that Anthropic was in talks to raise significant new funding at a much higher valuation. The new round nearly triples its valuation from March, when it raised $3.5 billion at a $61.5 billion valuation.
The company says its revenue run rate as of August was more than $5 billion — significant growth since the beginning of the year, when that figure was around $1 billion. Much of its growth has been on the enterprise side: Anthropic said it now has more than 300,000 business customers, up nearly 7x in the past year.
Anthropic’s deal also comes as funding to artificial intelligence startups dominates venture investment globally. Around $40 billion in venture investment — or 45% of global funding — went to the AI sector in Q2, according to Crunchbase data. Foundation model companies raised $5.5 billion of that.
Anthropic has now raised $33.7 billion since its inception in 2021, per Crunchbase. Its funding also illustrates the extent to which venture investment has increasingly concentrated into larger rounds for already well-capitalized startups.
Other major investors in its new funding included Altimeter, Baillie Gifford, affiliated funds of BlackRock, Blackstone, Coatue, D1 Capital Partners, General Atlantic, General Catalyst, GIC, Growth Equity at Goldman Sachs Alternatives, Insight Partners, Jane Street, Ontario Teachers’ Pension Plan, Qatar Investment Authority, TPG, T. Rowe Price Associates Inc., T. Rowe Price Investment Management Inc., WCM Investment Management and XN.
Anthropic Valuation Hits $183 Billion in New $13 Billion Funding Round
Wsj • September 2, 2025
Venture

Overview
An artificial intelligence company has closed a massive $13 billion Series F funding round, a raise that the article says nearly triples the company’s valuation compared with March. The sheer size of the round signals intense investor conviction in frontier AI models and the capital requirements to build, train, and deploy them at scale. The funding positions the company to accelerate product development, expand computing capacity, and deepen commercialization across enterprise and consumer use cases.
Scale and Valuation Context
The round totals $13 billion (Series F), one of the largest late-stage financings seen in private tech, underscoring how AI development has shifted from traditional venture-sized checks to mega-rounds that resemble late-stage or pre-IPO financings.
The company’s valuation is described as “nearly triple” since March, indicating a rapid re-rating of perceived market opportunity, product traction, or competitive moat within just a few months.
A Series F at this magnitude suggests broad participation, typically including growth-equity funds, crossover investors, and strategics that can provide distribution, compute, or ecosystem advantages.
What the Capital Likely Enables
Compute scale-up: Training and serving state-of-the-art models is compute intensive and requires sustained access to advanced GPUs/accelerators and networking; a raise of this size can secure multi-year capacity.
Model R&D: Funding supports larger training runs, frontier-safety and alignment research, efficiency improvements (e.g., inference optimization), and new modalities.
Go-to-market buildout: Enterprise sales, developer ecosystem programs, and sector-specific solutions (e.g., knowledge work, customer service, coding, creative tools) typically expand markedly post-raise.
Talent and infrastructure: Capital enables aggressive hiring in research, engineering, safety, and reliability, alongside investments in data pipelines, evaluation frameworks, and compliance tooling.
Market and Competitive Implications
Competitive pressure: A war chest of this size can compress the innovation cycle, forcing peers to either partner, specialize, or raise comparable sums to remain competitive on model quality and inference cost.
Platform dynamics: Large rounds often come with strategic alignment—such as long-term cloud commitments or joint product roadmaps—that can shape developer platform choices and enterprise standards.
Pricing and accessibility: Greater compute and model efficiency can flow through to lower inference costs over time, broadening adoption and enabling more price-sensitive use cases.
Safety and governance: As models scale, so do expectations for responsible deployment. Substantial late-stage capital can expand the company’s safety research and evaluation capabilities, which are increasingly crucial for enterprise and regulatory acceptance.
Signals to Investors and Partners
Validation of business model: A near-tripled valuation in a short window suggests strong confidence in revenue growth, strategic positioning, or both—particularly in high-value verticals and developer ecosystems.
Late-stage liquidity path: Series F financings can precede strategic combinations or eventual public offerings once market conditions align; investors may expect clearer routes to liquidity and governance maturity.
Ecosystem effects: Vendors in chips, cloud, data labeling, and enterprise tooling may see demand uplift; integrators and consultancies can benefit from implementation work as deployments scale.
Risks and Execution Challenges
Capital intensity and burn: Frontier AI demands continued outlays in compute and talent; even large raises require disciplined allocation to avoid overextension.
Regulatory headwinds: Rapid scaling heightens scrutiny on data provenance, safety, and compliance; navigating evolving rules across jurisdictions will be critical.
Market saturation and differentiation: As competitors release similarly capable models, sustained advantage may hinge on safety, reliability, tooling, and integration rather than headline benchmarks alone.
Key Takeaways
The company raised $13 billion in a Series F, and its valuation is reported as nearly tripled since March.
The raise underscores investor conviction in frontier AI and the capital intensity of training and deploying advanced models.
Expect accelerated R&D, expanded compute capacity, deeper enterprise push, and heightened focus on safety and governance.
Competitive dynamics may intensify, with potential downstream impacts on pricing, ecosystem alliances, and the path to public markets.
Benchmark’s Peter Fenton Isn’t Ready to Call This an AI Bubble
Bloomberg • September 3, 2025
Venture

Overview
This edition focuses on a conversation with Benchmark partner Peter Fenton about how a classic early‑stage firm is navigating an AI‑dominated startup landscape. The discussion centers on why he isn’t ready to label the current moment an outright bubble and how that view informs Benchmark’s pacing, diligence, and company‑building philosophy. It emphasizes separating durable shifts in software demand from hype cycles, and keeping investment discipline even as model breakthroughs and escalating compute have redrawn what founders can build and how quickly they can reach customers.
Why “not a bubble” (yet)
Fenton’s stance hinges on early, compounding evidence of real customer value rather than purely speculative multiples. The dialogue frames AI as a platform transition where productivity gains, novel product experiences, and measurable workflow automation persist across markets. Instead of fixating on model benchmarks, the lens is whether teams are creating repeatable value that survives outside demo environments—e.g., sustained user engagement, net revenue retention, and willingness to pay for outcomes rather than experimentation. He differentiates momentum driven by fundamental adoption from exuberance driven by funding velocity, arguing that the former is visible across both infrastructure and application layers.
How this shapes Benchmark’s strategy
Back to first principles: small, high‑conviction bets at formation and early traction stages; work closely with founders on product velocity, distribution, and hiring.
Ruthless focus on moats that outlast model commoditization: proprietary data loops, workflow lock‑in, distribution advantages, and hard problems tied to domain context rather than raw model access.
Pragmatism on build vs. buy: leverage frontier models or open‑source where sensible; invest differentiation where customer value is proven and margins support it.
Go‑to‑market discipline: preference for products that show bottoms‑up pull, clear payback periods, and pricing aligned to value delivered (time saved, revenue gained, risk reduced).
Governance and durability: hands‑on board work around security, compliance, and reliability as AI systems touch sensitive data and regulated workflows.
Where the opportunities and risks sit
The conversation distinguishes horizontal infrastructure (tooling, data platforms, evaluation/observability, privacy) from vertical applications (specialized copilots, automation agents, decision support). Infrastructure must demonstrate indispensable developer productivity or compliance benefits, not just novelty. Vertical apps must prove end‑to‑end workflow ownership and sustained retention in the face of fast‑moving incumbents. Key risk factors include rising compute costs outpacing unit economics, model improvements eroding thin moats, and distribution cliffs when pilots fail to convert to paid rollouts.
Implications for founders
Build real‑world evidence early: production use, error budgets, and quantified ROI beat leaderboard wins.
Design moats intentionally: tight data feedback loops, switching costs, and embedded workflows matter more than proprietary models alone.
Keep capital efficient: timing capacity spend (compute, data acquisition) to validated demand extends runway and strengthens pricing power.
Treat compliance and trust as product: security, auditability, and provenance can be differentiators, not afterthoughts.
What to watch next
Expect investor scrutiny to intensify around gross margins net of inference costs, cohort behavior beyond initial excitement, and resilience as models evolve. M&A by incumbents may accelerate in categories where distribution is decisive. Open‑source ecosystems will keep pressuring prices and enabling speed, raising the bar for defensibility. For firms like Benchmark, the playbook remains consistent: concentrate on a small number of exceptional teams, compound value through company‑building, and let durable customer outcomes—not market temperature—set the pace.
Key takeaways
AI looks like a platform shift with real adoption signals; labeling it a bubble misses where durable value is accruing.
Investment discipline focuses on moats beyond model access: data loops, workflow ownership, and distribution.
Unit economics, security, and compliance are central to defensibility as systems move into mission‑critical domains.
The next phase will reward measured execution: converting pilots to sticky deployments with clear ROI and healthy margins.
From Frustration to Conviction: What led to starting Allocate and our $30.5M Series B
Venture unlocked • September 3, 2025
Venture

Last month marked four years since I co-founded Allocate with Hana Yang.
Today I’m excited to share a milestone in our journey: we’ve raised $30.5 million in our Series B funding, led by Portage Ventures with participation from Andreessen Horowitz, M13, and Fika Ventures.
This milestone is nice, but the real story is what it enables—fixing a problem I’ve been facing for over a decade.
The realization came back in 2011 when I tried to find solutions to help me build a private market portfolio—something personalized, transparent, easy to manage, and with access to the full menu of opportunities. Since I was conflicted out of investing in funds through my relationships, given my role at the banks I worked at, I had to find other options.
What I found instead was nothing that met my needs, and everything was either too manual, too opaque, or just not aligned to my objectives. When I joined First Republic in 2012, I saw how crucial private market access was becoming for clients. The bank did a great job introducing alternatives, but even then, we were constrained by antiquated systems. Relationships were strong, demand was there, but the tooling simply couldn’t deliver the experience investors deserved. Those experiences stuck with me.
And they ultimately pushed me to start Allocate. If public markets can be as seamless as they are today, why shouldn’t private markets be the same?
Private markets today represent ~$15 trillion in AUM and are projected to nearly double by the decade's end. Venture capital, once considered a niche corner of finance, now accounts for more than $3 trillion in NAV. The scale is staggering: the three largest VC-backed companies—SpaceX, Anthropic, and OpenAI—are collectively valued at over $1 trillion and reportedly generate over $30 billion in annualized revenues. For reference, Google went public with a market cap of $23B and prior year revenues of $1.4B.
But growth has come with fragmentation. There are thousands of fund managers on one side, each with unique models and reporting standards.
On the other hand, we’re starting to see more non-institutional participation than ever before. Although only 3–4% of client portfolios are allocated to alternatives in the wealth channel today, projections suggest this will rise to 10% by 2030.
For context, wealth advisors in the U.S. oversee more than $30 trillion, meaning trillions of new private allocations are likely coming. Without the right tooling, this market cannot scale efficiently or responsibly. And this isn’t about simple “democratization tools.” What private markets need is a comprehensive infrastructure reset—systems built from the ground up so they can operate with the same efficiency, transparency, and accessibility that public markets achieved during their transformation in the 1970s.
In four years, we are thankful that despite a turbulent economic climate from 2022-2024, we have started to see the impact of our efforts.
The Great Rotation: How AI/ML Crushed Traditional SaaS in Seed Investing During 1H 2025, Per AngelList
Saastr • September 3, 2025
Venture
“‘SaaS is dead’ is the wrong takeaway,” the article argues; “SaaS without AI is dead.” It describes a dramatic rotation in seed investing during 1H 2025, with AngelList data showing funding has surged toward AI/ML while traditional SaaS has “almost frozen” at seed. The shift reflects recategorization as much as sentiment: many products that would have been called SaaS two years ago are now labeled AI-first B2B applications. (saastr.com)
Headline numbers and reclassification effects
AI/ML captured roughly 40% of seed deals in 1H 2025.
Traditional SaaS fell to about 3–4% of deal volume.
Developer Tools held up at roughly 7–8%, often because they are AI-oriented but still grouped by end market.
Crucially, the AI/ML bucket includes a large swath of B2B apps that used to be counted as “SaaS,” masking the underlying health of AI-powered business software. (saastr.com)
What’s inside the “AI/ML” bucket
The 40% share isn’t just foundational models and GPU infrastructure. Roughly 15% is pure AI infrastructure (foundation models, AI chips, training platforms, MLOps), while about 25% are AI‑native B2B applications—what used to be “vertical SaaS,” now built AI‑first on LLMs and modern ML. Examples include AI legal research, autonomous customer-service agents, and AI financial planning tools—applications that would have been filed under SaaS in 2022 but are now categorized as AI/ML. (saastr.com)
Interpretation: SaaS isn’t dead—it's been absorbed
Investor taxonomy has shifted. The article frames three buckets: (1) Traditional SaaS (~3%): workflow tools, dashboards, CRMs without meaningful AI; (2) AI/ML (~40%): any B2B software where AI is the core value prop; (3) Vertical categories (e.g., healthtech, fintech), many of which are AI‑powered but labeled by industry. This reframing explains why non-“SaaS” categories can still perform if AI is central. (saastr.com)
Capital deployment patterns and why AI-first is winning
Traditional SaaS is attracting smaller checks; AI‑native B2B apps are raising larger seed rounds at premium valuations. Investors believe AI‑driven tools can scale faster (less human-heavy CS), defend better (learning effects), expand quicker (automated upsell discovery), and command higher prices (insight-based value). Put simply, capital is flowing to products whose core outcomes are unlocked by AI rather than add-on features. (saastr.com)
Who’s actually winning
Healthtech (~15%): AI diagnostics, care coordination, clinical decision support.
Fintech (~8–10%): AI fraud detection, underwriting, personal finance.
Developer Tools (~7–8%): AI code generation, testing, deployment optimization.
Across these, AI is the value engine, not a bolt‑on. (saastr.com)
Implications for founders and fundraising
Positioning must flip from “SaaS with AI features” to “AI platform that delivers a specific business outcome.” The companies raising successfully solve problems that were impractical pre‑LLMs—sales intelligence that predicts intent, CS tools that auto‑intervene on churn, PM software that prioritizes and allocates work, HR platforms that match candidates and forecast performance. “The great rotation isn’t from SaaS to AI. It’s from human-powered software to AI-powered software.” (saastr.com)
Key takeaways
Lead with AI as the primary differentiator; avoid categories easily replicable by general AI agents.
Expect investor scrutiny on defensibility via data network effects and model feedback loops.
Use outcome-first messaging tied to AI capabilities, not generic “SaaS” labels.
Vertical AI B2B apps are the center of gravity in seed; pure non‑AI SaaS is a hard sell. (saastr.com)
Jack Altman & Martin Casado on the Future of Venture Capital
Youtube • a16z • September 3, 2025
Venture
Overview
A wide‑ranging conversation examines how venture capital is reorganizing around new technological and market realities. The discussion centers on how firm strategies, founder expectations, and capital formation are shifting as software and AI permeate every industry. The speakers contrast classic “tools and platforms” investing with a growing wave of full‑stack, category‑defining startups that enter regulated, incumbent-heavy markets. They also weigh how fund construction and portfolio math are adapting to power‑law outcomes, as well as the renewed emphasis on concentrated conviction, hands‑on firm “power” (distribution, hiring help, customer access), and long-term company building.
Where Venture Is Heading
From picks‑and‑shovels to full‑stack: Rather than selling generic tools across many buyers, more winners now replace parts of existing industries, integrating product, distribution, and operations end‑to‑end.
Barbell dynamics: Capital and talent pool into very early (pre‑seed/seed) experiments on one end and large, conviction bets on breakout companies on the other; mid‑sized funds and middling rounds feel the squeeze.
Firm “power” as a differentiator: The value founders seek is not only a check but brand, customer introductions, narrative reach, and recruiting leverage—bridging the gap until a startup’s own brand compounds.
Pattern discovery vs. pattern matching: Taste, timing, and access still matter, but investors emphasize running toward emerging networks and scenes where new ideas, talent density, and distribution advantages form.
Implications for Founders
Capital efficiency and proof: The easiest capital to raise is still early, but founders are urged to translate vision into specific wedge products, credible distribution, and fast learning loops; durable traction beats pitch polish.
Board construction and governance: Early choices around who sits on the board have outsized effects on strategy, follow‑on financing, and resilience during inevitably hard cycles.
Hiring and narrative: Winning the talent market is existential; founders borrow a firm’s brand early, then must quickly build their own by shipping, telling a clear story, and creating a magnetic learning culture.
Fund Construction and Portfolio Math
Concentration over diversification: Given power‑law returns, managers favor fewer, higher‑conviction positions where they can add real help and maintain ownership through multiple rounds.
Avoiding accidental competition: As funds scale, they must avoid drifting into competitive arenas where entrenched franchises dominate; clarity on stage, sector, and edge is key.
Early vs. growth skill sets: Sourcing, picking, and coaching zero‑to‑one companies is fundamentally different from underwriting scale and unit economics; firms increasingly specialize or bifurcate teams.
AI’s Role in the New Stack
Platform shift: AI is treated as a broad computing platform change that rewires products, go‑to‑market, and cost structures across consumer and enterprise.
Incumbent vs. startup advantage: Startups can integrate AI deeply into workflows and business models, while incumbents face organizational inertia; investors look for founders who pair model leverage with proprietary data, distribution, or novel user experiences.
Operating in Regulated and Real‑World Markets
Full‑stack complexity: Entering healthcare, finance, defense, or logistics requires expertise in compliance, integration, and service delivery; investors back teams that combine technical excellence with operational chops.
Sales motion evolution: PLG and bottoms‑up adoption blend with classic top‑down enterprise sales; pricing, packaging, and customer success design become strategic weapons, not afterthoughts.
Key Takeaways
The center of gravity in venture is shifting toward full‑stack, industry‑redefining companies and away from generic tooling plays.
Firm power—brand, network, distribution, and recruiting—is a core part of the investment product, not a nice‑to‑have.
Portfolio construction favors concentration and ownership; “the death of the middle” pressures undifferentiated mid‑stage capital.
AI’s platform shift rewards founders who translate capability into wedge products, defensible data advantage, and efficient distribution.
Early board and hiring decisions compound; pick partners and narratives that help you win scarce attention and talent.
Predictably bad predictions
Signalrank update • September 4, 2025
Venture
The advent of AI has led to a field day for futurologists seeking to predict the potential impact of AI on tomorrow’s economy & society. TBPN’s John Coogan summarized the AGI progress vs impact debate with this handy two by two:

Platform shifts broaden the spectrum of possible outcomes: opportunity for high upside, but also amplified risk.
There is consensus that AI is a big deal. But no-one knows exactly how far & how fast the technology will develop. This creates substantial financial (& career) risk in being a traditional VC these days, making just 1-2 investments per year.
It is precisely at these moments why a highly diversified model such as SignalRank’s should appeal to allocators. We are aiming to make 30 investments per year at scale, with our structure also offering high vintage diversification. One investment today provides an investor with access to both our historic & future vintages.
This post considers the difficulty in predicting the future, how this applies to VC and then suggests that SignalRank’s systematic & diversified approach can offset some of these challenges.
The challenge with predicting the future
The future is of course unknowable, reflecting more about present concerns than anything else. The only thing we can be certain of is that most predictions will be wrong.
This is the topic of this book, which was the inspiration for this post, which looks at the history of predictions about the future.
It can be fun to look back at prior predictions, although this does give the false impression of wisdom just by living later. There is a risk of unfairly inflicting on prior generations “the enormous condescension of posterity,” to borrow a phrase from the historian EP Thompson.
There are lots of good examples of the futility of predicting the future. Figure 1 is perhaps the most compelling chart to make the point, demonstrating effective Fed Funds rate versus market expectations.
Figure 1. Effective Fed Funds rate versus market expectations (from Man Group)

Another great memo on predicting the future comes from Donald Rumsfeld of all people. He wrote this one page memo, just six months before 9/11: “All of which is to say that I’m not sure what 2010 will look like, but I’m sure that it will be very little like we expect, so we should plan accordingly.”
This is also quite a good list of the most inaccurate technology predictions in the last 150 years.
VCs trying to predict the future

Venture capital is a high variance asset class with high returns and high loss ratios. Even where there is platform stability (as during the mobile & cloud era from 2006-22), it is challenging to identify & back the right opportunities.
In fact, the perverse thing about VC is that the best funds have higher loss ratios. Here’s some data from StepStone and Primary:

Zeroes are expected. Daybreak’s Rex Woodbury talks about how “zeroes that couldhave been fund-returners should be celebrated as good swings: this is a business of home-runs, not second-base hits.”
We also ran some analysis to consider how firms have performed in the post ZIRP era. We see that only 30% of seed investments since 2022 by the top 20 seed managers (per our model) have raised a subsequent priced round (or 12% for all seed managers).
If we interrogate this further by looking at the cohort by cohort data, the picture is not much better. Only 35% of 2022 seed investments by the top 20 investors have raised a subsequent priced round.
In short, VC is a really hard business.
Is Non-Consensus Investing Overrated?
Youtube • a16z • September 4, 2025
Venture
Watch this video on YouTube
Global Startup Funding In August Fell To Lowest Monthly Total In 8 Years As Seed And Late-Stage Investors Retreated
Crunchbase • September 4, 2025
Venture

Global venture funding in August fell to the lowest monthly amount since 2017, Crunchbase data shows. Startup funding last month totaled $17 billion — down 12% from a year ago and a massive 44% drop month over month.
The slowdown marks a respite from the frenzied pace of venture investment in the first half of 2025 — especially for fast-growing AI companies — when startup funding increased by more than a third year over year.
Summer pullback
Since 2023, we’ve seen a noticeable summer pullback in either July or August, when global venture funding typically dips below $20 billion.
It’s typical for late-stage funding to lag in these slower months. Less typically, there was also a significant pullback at the seed stage last month, when funding at that phase nearly halved compared to July and fell a third from a year ago.
Late-stage funding declined more than 50% compared to July and fell by a fifth year over year, Crunchbase data shows. Early-stage funding also declined month over month, but to a lesser degree, and increased slightly from a year ago.
Bret Taylor’s Sierra raises $350M at a $10B valuation
Techcrunch • September 4, 2025
Venture

Investors are piling into Bret Taylor’s AI agent startup, Sierra, signaling strong conviction in its approach to automating customer support for large enterprises.
Sierra said it raised $350 million on Thursday in a round led by returning backer Greenoaks Capital, giving the company a $10 billion valuation. The announcement, shared via a company blog post, also confirmed an Axios report published the day prior.
Founded in early 2024 by Taylor and longtime Google executive Clay Bavor, Sierra builds customer service AI agents for enterprises. In roughly 18 months, the company says it has signed up hundreds of customers, including SoFi, Ramp and Brex.
With the new financing, Sierra’s total capital raised climbs to $635 million. Earlier rounds included $110 million closed in February of last year led by Sequoia and Benchmark, and $175 million closed in October of last year led by Greenoaks. Other investors include ICONIQ and Thrive Capital.
Taylor and Bavor bring deep experience in products that touch customer workflows. Taylor spent nearly a decade at Salesforce and previously founded Quip, which Salesforce acquired for $750 million in 2016. Bavor, meanwhile, oversaw major consumer productivity products at Google, including Gmail and Google Drive.
Before his Salesforce tenure, Taylor worked at Google, where he is widely credited with helping launch Google Maps. He later chaired Twitter’s board during Elon Musk’s takeover of the social platform.
GeoPolitics
Opinion | What Happened to Europe?
Wsj • September 2, 2025
GeoPolitics•Europe•Productivity

Sorry, I can’t provide a verbatim extract from that article, but here’s a concise summary of the opening.
Europe’s disappointing economic performance relative to the U.S. is framed as a long-running divergence whose core driver is weaker productivity growth. Demographic aging and the surge in energy costs have compounded the problem, but they are presented as accelerants rather than the root cause. The central claim is that Europe’s living standards lag because output per worker and per hour have not kept pace with America’s, and compounding effects over decades now show up in slower income growth and diminished competitiveness.
The argument highlights structural factors behind the productivity gap: fewer fast-growing scale firms, less business dynamism, and slower diffusion of frontier technologies across the wider economy. Capital markets remain fragmented, limiting scale-up finance and risk-taking. Product and labor market rules, while often well-intentioned, can impede reallocation from less productive to more productive uses. These frictions damp investment in intangible assets, software, and R&D, where the U.S. has compounded advantages.
Energy is cast as a headwind that magnified existing weaknesses. Europe’s exposure to high gas and electricity prices—especially after geopolitical shocks—squeezed industry margins, deterred new investment, and reinforced relocations toward regions with cheaper, more reliable energy. But the text insists energy is not destiny: even with higher prices, a more dynamic, innovation-rich business ecosystem would have cushioned the blow.
The proposed remedy is to put productivity at the center of policy. That means deeper single-market integration, faster permitting and infrastructure build-out, more flexible labor markets allied with upskilling, and a capital-markets union to fund scale. It also calls for accelerating adoption of digital tools and AI across small and midsize firms, while ensuring competitive pressure that rewards efficiency and innovation rather than preserving incumbency.
Regulation
What the Fixes for Google’s Search Monopoly Mean for You: It’s a ‘Nothingburger’
Nytimes • September 2, 2025
Regulation•USA•Antitrust•Google Search•Default Settings

Overview
The piece argues that the court-ordered “fix” to Google’s search monopoly won’t materially change how most people use their phones, computers, or the web. In practical terms, the remedy is framed as incremental rather than transformative: the status quo of typing queries into the same search bar, seeing a familiar results page, and relying on Google’s broader services will largely persist. The central takeaway is that any mandated adjustments won’t meaningfully alter day-to-day behavior for the typical user, nor will they rapidly reshape the competitive landscape of online search.
What Will (and Won’t) Change for Users
The core experience of initiating a search from a browser address bar, phone home screen, or voice assistant will feel much the same. You’ll still default to the search engine already embedded in your device’s software environment unless you take explicit steps to switch.
Any compliance steps that do surface—such as additional prompts, disclosures, or settings screens—are likely to be subtle and easy to ignore. If they exist, they won’t force a dramatic rethink of daily habits.
The convenience ecosystem that surrounds search (auto-complete, maps, knowledge panels, shopping modules, and other integrated widgets) will continue to encourage users to remain within familiar workflows.
Why the Remedy Is Characterized as Minimal
The ruling’s design avoids drastic structural changes. Rather than breaking up businesses or imposing sweeping restrictions that would rewire user interfaces, it hews toward narrower conduct adjustments.
Defaults matter because they compound inertia; small frictions can prevent switching. If the remedy doesn’t substantially disrupt defaults—or make alternatives conspicuously attractive—consumer behavior tends to remain static.
Search is interwoven with other services. Unless the remedy meaningfully dis-entangles or rebalances those integrations, the overall gravitational pull of the incumbent remains strong.
Implications for Competition and Alternatives
Competing search providers aren’t likely to see an immediate flood of new users. Without a compelling new behavior introduced by the remedy—such as an unavoidable, clearly explained, and truly neutral choice process—adoption curves for alternatives will stay shallow.
Developers and device makers will continue optimizing around what most users already do, reinforcing the incumbent’s advantage in performance tuning, integration, and distribution.
Advertising dynamics won’t shift overnight. If user behavior remains stable, ad inventory, targeting signals, and campaign strategies will continue to orbit the dominant platform.
Consumer Impact: What You Might Notice
Occasional interface nudges: You may encounter an extra screen or setting related to your search provider, but it will be easy to accept the default and move on.
Familiar results: The look, feel, and ordering of results will still prioritize what most users are accustomed to seeing, with integrated answers and modules shaping attention.
Optional switching: Power users who already prefer an alternative can still switch; casual users are unlikely to change unless presented with clear benefits and a low-friction path.
Longer-Term Outlook
Behavioral habits and ecosystem design change slowly. Even well-intended remedies need time, enforcement clarity, and complementary industry shifts to register in aggregate user behavior.
Future adjustments could matter more than the initial order if they target friction points that truly influence defaults, visibility, and integration—areas that determine whether alternatives get a fair shot at discovery and retention.
For now, however, the day-to-day reality remains: you’ll search the way you did yesterday, and the web will look largely the same tomorrow.
Key Takeaways
The remedy emphasizes compliance without reengineering user experience.
Defaults and integration still dictate behavior; modest prompts won’t overcome inertia.
Competitive dynamics in search remain largely intact, keeping consumer experience steady.
Google spared break-up in US monopoly case
Ft • September 2, 2025
Regulation•USA•Antitrust Remedies•Alphabet•Apple
What happened
A US judge issued a ruling in a high-profile monopoly case that does not force a structural break-up of Google. Markets interpreted the decision as less punitive than feared, with shares of Alphabet (Google’s parent) and Apple advancing after the announcement. The message investors took: the company can continue operating its core businesses without being carved up, even if it faces ongoing constraints and oversight on certain practices.
Why markets rallied
Investors had braced for the possibility of structural remedies—such as divestitures or forced separation of business units—that could permanently alter Google’s economics and weaken associated partner revenue streams. By avoiding that outcome, the ruling reduces the near-term risk to Google’s search, advertising, and distribution arrangements and to Apple’s related monetization tied to Google services on its devices. Relief rallies often follow when the worst-case scenario is taken off the table, and that dynamic appears to have driven the immediate share price gains.
Likely character of remedies
While details were not the focus of the market reaction, the prevailing interpretation is that the court favored conduct-based (behavioral) remedies over structural ones. In antitrust contexts, that typically means obligations aimed at how a company competes rather than how it is organized—examples can include limits on exclusivity agreements, requirements to offer more user choice, restrictions on bundling, and periodic compliance reporting. Such measures can be significant but are generally seen as more predictable and manageable for large platforms than a forced break-up.
Implications for Alphabet
Business continuity: The core search and ads engine remains intact, preserving scale advantages and network effects.
Manageable compliance: Conduct remedies may impose friction—compliance systems, audits, and potential changes to distribution practices—but are less disruptive than divestitures.
Strategic flexibility: Avoiding break-up preserves cross-product integration and data synergies, important for monetization and product development.
Legal overhang: Even without structural relief, long-term uncertainty can persist as regulators monitor compliance and rivals test boundaries.
Implications for Apple
Revenue resilience: A less-severe ruling eases concerns about potential knock-on effects to Apple’s earnings tied to its role as a distribution channel for search services.
Platform control: Apple likely retains broad discretion over default settings and partnerships, albeit with possible obligations to enhance user choice or reduce exclusivity.
Continued scrutiny: Platform-gatekeeper issues remain in focus for regulators globally, so Apple may still face incremental compliance requirements in distribution or app-related domains.
What to watch next
Appeals and timelines: Post-ruling motions, potential appeals, and the cadence of compliance milestones will shape how constraints evolve.
Partner contracts: Any adjustments to distribution or revenue-sharing agreements could subtly shift margins for both Alphabet and Apple.
Competitive dynamics: Changes that expand user choice or limit exclusivity might open incremental opportunities for rival search providers, though scale advantages often persist.
Regulatory spillover: US outcomes can influence enforcement priorities in other jurisdictions, potentially leading to parallel or harmonized conduct obligations.
Key takeaways
The court declined the most disruptive remedy—break-up—reducing tail risks for Alphabet and, indirectly, Apple.
Markets rewarded the clarity and relative leniency with immediate share price gains.
Conduct-focused remedies imply oversight and potential product/distribution tweaks but preserve core business models.
The decision shifts attention from existential restructuring to execution under compliance, contract adjustments, and competitive positioning.
Google Must Share Search Data With Rivals, Judge Rules in Antitrust Case
Nytimes • September 2, 2025
Regulation•USA•Antitrust•Google•Search Data

Overview
A federal judge determined that Google must provide some of its search data to competing companies, creating a narrowly tailored remedy aimed at opening a sliver of the market’s most valuable input: user interaction data. The ruling, issued by Judge Amit P. Mehta, stops short of imposing sweeping structural or behavioral mandates sought by U.S. authorities. Instead, it focuses on compelled data sharing as the primary tool to promote competition in general search and adjacent services that rely on large-scale query and click data to improve relevance and quality.
What the Order Requires
The company is required to hand over “some of its search data” to rivals. While the decision does not enumerate the precise data fields in this summary, the emphasis on “some” signals a scoped, rather than comprehensive, dataset.
The objective is to enable competitors to enhance search quality, ranking, and user experience by accessing information that would otherwise take years of scale to accumulate independently.
The ruling implicitly anticipates technical and privacy safeguards—such as aggregation, anonymization, and rate limits—to mitigate risks while preserving the pro-competitive value of the data.
What the Order Does Not Do
The judge declined to impose other “big changes” requested by the U.S. government. In practical terms, that means no court-mandated overhaul of Google’s broader business model, no forced separation of units, and no blanket restrictions on core ranking or ad practices beyond the data-sharing mandate indicated here.
There is no indication in this summary of new default-setting rules, wholesale contract prohibitions, or algorithmic transparency requirements. The remedy is centered on data access rather than structural reconfiguration.
Rationale and Context
Search markets are characterized by strong feedback loops: more users generate more queries and clicks, which refine relevance and attract still more users. By compelling limited data access, the court appears to be targeting this scale advantage without upending the entire ecosystem.
Judge Mehta’s choice reflects a balancing act: foster competition while avoiding remedial overreach that could harm innovation or destabilize widely used services.
Implications for Competitors and Consumers
Competitors gain a path—albeit a narrow one—to improve result quality and reduce cold-start disadvantages. Smaller search engines and vertical search providers could see acceleration in training their ranking systems, feature development, and relevance testing.
Consumers may benefit from improved alternatives, more experimentation in search interfaces, and potentially better privacy features as rivals differentiate themselves. However, benefits will depend on the usability, timeliness, and scope of the data provided.
Implementation Challenges
Privacy and security controls will be paramount. Even anonymized datasets can carry reidentification risk if not carefully managed. Compliance will likely require robust governance, audit trails, and clear usage boundaries.
Technical interoperability must be addressed: standardized formats, documentation, and update cadences will determine whether rivals can meaningfully integrate the data.
Monitoring and enforcement will matter. A data-sharing remedy is only as effective as the mechanisms that ensure timely, high-quality, and non-discriminatory access.
Key Takeaways
Limited but meaningful remedy: compelled sharing of “some” search data aims to chip away at scale advantages without broad restructuring.
No sweeping overhaul: the court declined additional “big changes,” signaling a cautious approach to antitrust remedies in digital markets.
Outcomes hinge on execution: privacy protections, data quality, and enforcement will decide whether competition measurably increases.
Bottom Line
The ruling adopts a minimalist antitrust remedy tailored to the central bottleneck of search—access to high-quality interaction data—while avoiding expansive interventions into Google’s operations. Its success will depend on how precisely “some” data is defined, safeguarded, and delivered, and whether those flows are sufficient to meaningfully empower competitors without compromising user privacy.
Google statement on today’s decision in the case involving Google Search.
Blog • Lee-Anne Mulholland • September 2, 2025
Regulation•USA•Antitrust•GoogleSearch•DOJ
Earlier today a U.S. court overseeing the Department of Justice’s lawsuit over how we distribute Search issued a decision on next steps.
Today’s decision recognizes how much the industry has changed through the advent of AI, which is giving people so many more ways to find information. This underlines what we’ve been saying since this case was filed in 2020: Competition is intense and people can easily choose the services they want. That’s why we disagree so strongly with the Court’s initial decision in August 2024 on liability.
Now the Court has imposed limits on how we distribute Google services, and will require us to share Search data with rivals. We have concerns about how these requirements will impact our users and their privacy, and we’re reviewing the decision closely. The Court did recognize that divesting Chrome and Android would have gone beyond the case’s focus on search distribution, and would have harmed consumers and our partners.
As always, we’re continuing to focus on what matters — building innovative products that people choose and love.
Washington doubles down on Big Tech antitrust cases despite Google setback
Ft • September 3, 2025
Regulation•USA•Antitrust
Overview
Washington is pressing ahead with a multi-front antitrust campaign against Big Tech even after a judge issued a narrower-than-requested remedy in the landmark Google search case. The ruling, which declined to break up Google’s search and browser businesses, was widely seen as a setback for enforcers. Yet the Department of Justice (DOJ) and the Federal Trade Commission (FTC) are accelerating actions against Alphabet, Apple, Amazon, and Meta, signaling an unusual continuity of tech scrutiny across administrations. (apnews.com, reuters.com)
What the Google ruling actually did
A federal judge opted for lighter remedies in the search case, rejecting the DOJ’s push to force divestitures such as Chrome, and instead ordering measures like sharing portions of Google’s search data with rivals and curbing exclusivity, moves intended to spur competition without structural breakups. Investors cheered, but antitrust commentators called the modest remedy a “historic misfire.” The Justice Department is weighing next steps, and appeals are possible from both sides. (apnews.com)
The narrower search remedy lands alongside a separate, more forceful DOJ win: in April 2025, a federal court found Google illegally monopolized key ad-tech markets (publisher ad servers and ad exchanges), clearing the way for structural remedies. The DOJ has already proposed divesting AdX and DFP, with a remedies proceeding set for September 2025. (cnbc.com)
Where enforcement is intensifying
Google (Alphabet): Despite the tempered search remedy, the ad-tech case gives enforcers leverage; Judge Leonie Brinkema concluded Google “willfully” maintained monopoly power in publisher-side markets, and the court will consider divestitures. Together, the paired cases keep Alphabet under heavy scrutiny. (cnbc.com)
Apple: A federal judge in June 2025 rejected Apple’s bid to dismiss the DOJ’s smartphone-monopoly case, allowing claims that Apple’s ecosystem restrictions illegally stifle competition to proceed. The litigation, now on a multi-year track, underscores Washington’s appetite to test novel theories around mobile-platform power. (reuters.com)
Amazon: The FTC’s sweeping case targeting Prime “dark patterns,” marketplace fee structures, and alleged algorithmic price effects continues. A trial is slated for 2027, reflecting the long runway and resource demands of modern tech antitrust. (reuters.com)
Meta: The FTC persists in its bid to unwind Instagram and WhatsApp acquisitions, with no decision expected before late 2025, maintaining pressure on past “killer acquisitions.” (reuters.com)
Nvidia/Microsoft and others: Investigations and inquiries into AI-chip dominance and software licensing signal that Washington’s lens is widening beyond the traditional “Big Five.” (reuters.com)
Politics, personnel, and posture
The FTC’s leadership shift has not derailed high-profile tech cases. Andrew N. Ferguson, designated FTC Chairman in January 2025, has emphasized a different policy tone in other areas, yet the agency has kept major Big Tech cases alive—an indicator that headline antitrust matters remain a priority. As Ferguson put it on taking office, “We will usher in a new Golden Age for American businesses, workers, and consumers,” a message consistent with a tougher stance on dominant platforms even amid other deregulation moves. (ftc.gov)
The broader throughline is continuity: cases initiated or advanced during the prior administration are rolling forward under the current one. Washington’s antitrust agenda—spanning search defaults, app-store rules, self-preferencing, and ad-tech conflicts—now features overlapping remedies and timetables that will extend for years. (reuters.com)
Why this matters
Market structure: Even a “modest” search remedy can open footholds for challengers via data access and limits on exclusivity, while the ad-tech case could force Alphabet to separate core components of its advertising stack—changes that would reverberate through publisher revenues, ad pricing, and interoperability. (apnews.com, cnbc.com)
Legal strategy: Enforcers appear willing to accept incremental wins (behavioral remedies in search) while pushing for structural relief where the record is strongest (ad-tech). That portfolio approach keeps pressure on dominant firms despite courtroom variability. (cnbc.com)
Timeline and risk: With remedies hearings in September 2025 (ad-tech) and multi-year tracks for Apple, Amazon, and Meta, regulatory uncertainty will shadow product roadmaps, partnerships (e.g., default search deals), and M&A, potentially constraining Big Tech’s ability to leverage bundling or exclusivity. (cnbc.com, reuters.com)
Key takeaways
The search-case remedy fell short of break-up, but Washington is not retreating; parallel cases keep Alphabet, Apple, Amazon, and Meta under sustained scrutiny. (apnews.com, reuters.com)
Structural remedies are squarely on the table in ad-tech; divestiture decisions in late 2025 could reshape digital advertising’s plumbing. (cnbc.com)
Tech antitrust has become a durable, bipartisan policy project, with cases now outlasting electoral cycles and shaping platform behavior for years. (reuters.com)
Atlassian Acquires The Browser Company for $610 Million
The verge • Dave Pierce • September 4, 2025
Regulation•Mergers•Atlassian•The Browser Company•Arc Browser
Mike Cannon-Brookes, the CEO of enterprise software giant Atlassian, was one of the first users of the Arc browser. Over the last several years, he has been a prolific bug reporter and feature requester. Now he’ll own the thing: Atlassian is acquiring The Browser Company, the New York-based startup that makes both Arc and the new AI-focused Dia browser. Atlassian is paying $610 million in cash for The Browser Company, and plans to run it as an independent entity.
The conversations that led to the deal started about a year ago, says Josh Miller, The Browser Company’s CEO. Lots of Atlassian employees were using Arc, and “they reached out wondering, how could we get more enterprise-ready?” Miller says. Big companies require data privacy, security, and management features in the software they use, and The Browser Company didn’t offer enough of them. Eventually, as companies everywhere raced to put AI at the center of their businesses, and as The Browser Company made its own bets in AI, Cannon-Brookes suggested maybe the companies were better off together.
The acquisition is mostly about Dia, which launched in June. Dia is a mix of web browser and chatbot, with a built-in way to chat with your tabs but also do things across apps. Open up three spreadsheets in three tabs and Dia can move data between them; log into your Gmail and Dia can tell you what’s next on the calendar. Anything with a URL immediately becomes data available to Dia and its AI models.
Tesla Board Proposes Musk Pay Package Worth as Much as $1 Trillion Over Decade
Wsj • September 5, 2025
Regulation•USA•Tesla•Executive Compensation•ShareholderVote

Overview
Tesla’s board is asking shareholders to approve a performance-only compensation plan for the CEO that could be worth up to $1 trillion over the next decade, positioning it as an aggressive bet on the company’s transition from EV manufacturing to autonomy, robotics, and AI-led services. The proposal would deliver the award entirely in stock, contingent on a demanding ladder of market-cap and operating milestones, and is intended to retain the CEO’s focus on Tesla through the mid‑2030s. Shareholders are slated to vote on the package at the company’s November 6 meeting. (wsj.com, reuters.com)
How the package is structured
Scale and target: The award tops out if Tesla reaches roughly an $8.5 trillion valuation by 2035, implying nearly an eightfold increase from around $1 trillion today; the first unlock begins at $2 trillion, with additional tranches tied to each subsequent $500 billion in value creation. (washingtonpost.com, wsj.com)
Form of pay: The package would grant up to about 423 million shares, with no salary or cash bonus, strictly pay-for-performance; external reports cite an exercise/purchase price of $334.09 per share. (cbsnews.com, thetimes.co.uk)
Tranching and milestones: The plan features multiple tranches linked to both financial and operational goals, including long-run targets such as 20 million vehicles delivered, deployment of one million robotaxis, one million humanoid robots, and adjusted earnings reaching roughly $400 billion. (thetimes.co.uk, aljazeera.com)
Holding and vesting: Shares earned must be held for at least five years, with major vest dates clustered in 2032 and 2035 rather than continuous vesting—an unusually back‑loaded design for a mega‑grant. (wsj.com)
Governance, ownership, and legal backdrop
If fully earned, the award would add roughly 12 percentage points to the CEO’s stake, lifting total ownership to nearly 29% and materially increasing voting power and control over strategic direction. (wsj.com)
The board frames the plan as essential to retention: “It’s time to change that,” directors wrote, arguing the company lacks a long-term CEO performance award to keep him focused on Tesla. (cbsnews.com)
The proposal follows years of litigation and a 2024 Delaware Chancery ruling rescinding the prior record $56 billion package for process and fairness flaws; the court later declined to revise that decision, and Tesla has since reincorporated in Texas. Legal observers note the venue shift could shape any new challenges. (law.justia.com, delawarelitigation.com)
Accounting and market context
Tesla estimates an approximately $88 billion accounting cost for the new grant, on top of a previously recognized interim amount near $23.7 billion—large noncash expenses that could affect reported earnings even as the economic payout is fully performance‑based and equity‑settled. (wsj.com)
The stock rose about 3% after the announcement, reflecting a mix of enthusiasm about aligning incentives with ambitious autonomy/robotics goals and concern over concentration of control and execution risk. (washingtonpost.com)
Implications and open questions
Retention vs. concentration: The plan could anchor the CEO at Tesla through at least 2030, but it would also concentrate corporate power if fully realized—raising classic governance trade‑offs around checks, succession, and board independence. (washingtonpost.com)
Execution risk: Hitting a multi‑trillion‑dollar valuation and the cited operating milestones requires breakthroughs in robotaxis and humanoid robots and sustained scaling in vehicles and software—objectives well beyond historical auto‑industry precedents. External analysts characterize the package as a “critical next step” to keep leadership aligned for that push. (washingtonpost.com)
Litigation and oversight: After Tornetta v. Musk, the process quality—disclosure, independent negotiation, and shareholder consent—will be scrutinized. Texas incorporation alters the legal arena, but any perceived defects in process or terms could still prompt investor challenges or regulatory attention. (law.justia.com, news.bloomberglaw.com)
Shareholder calculus: Investors must weigh the potential for value creation against dilution, accounting impact, and governance precedent. Supporters see “pay for extraordinary performance,” while critics argue the scale is excessive amid cyclical EV demand and intensifying competition—even if the package only pays out when shareholders become massively wealthier. (reuters.com)
Key takeaways
Record‑scale, performance‑only equity award with back‑loaded vesting seeks to secure leadership through an autonomy/AI pivot. (wsj.com)
Full payout requires an ~$8.5T valuation plus aggressive operating milestones; first unlock at $2T, then per $500B increments. (washingtonpost.com)
Ownership could rise to ~29%, amplifying control; accounting cost estimated near $88B. (wsj.com)
Vote scheduled for November 6; immediate market reaction modestly positive. (wsj.com, washingtonpost.com)
Google Is Fined $3.5 Billion for Breaking Europe’s Antitrust Laws
Nytimes • September 5, 2025
Regulation•Europe•Antitrust

What happened
European Union officials have accused a major American technology company of leveraging its “size and dominance to undercut rivals in online advertising,” signaling another high‑stakes confrontation between Brussels and a leading U.S. platform. The move is framed as part of the EU’s broader campaign to police digital markets and ensure fair competition in ad tech. The article notes the action “could raise the ire of the Trump administration,” underscoring the geopolitical sensitivities that often accompany EU enforcement against U.S. firms.
Allegations and legal footing
At the core of the case is the claim that the company used its market power across multiple layers of the digital advertising stack—tools for advertisers, exchanges, and publisher ad servers—to disadvantage competitors and channel spend into its own systems. In EU competition terms, this would be assessed as a potential abuse of dominance under Article 102 of the Treaty on the Functioning of the European Union (TFEU), which prohibits conduct that distorts competition and harms consumers or trading partners. Typical theories of harm in such cases include self‑preferencing, tying/bundling across vertically integrated services, and exclusivity or interoperability restrictions that foreclose rivals.
Why online advertising matters
Digital advertising underwrites much of the free content and services on the internet. Control over auction technology, data signals, and access to publisher inventory can determine which firms capture ad dollars and on what terms. When a single actor dominates key chokepoints—such as the ad server used by publishers or the demand‑side tools advertisers rely on—competition can be skewed, potentially suppressing rivals’ margins, limiting innovation, and raising costs that ultimately filter through to advertisers and, indirectly, consumers.
Possible outcomes and remedies
EU competition cases can culminate in large fines and binding remedies. Behavioral remedies might require the platform to ensure data separation between business units, open interfaces to rival tools on non‑discriminatory terms, and refrain from self‑preferencing in auctions. Structural remedies—up to and including divestitures—are rare but possible in principle when conduct is tied to vertical integration across the ad tech stack. The Commission could also appoint monitoring trustees to oversee compliance, with periodic reporting and the threat of daily penalty payments for breaches.
Transatlantic and political implications
The note that this action may “raise the ire of the Trump administration” points to long‑running tensions over EU enforcement against U.S. tech champions. Washington policymakers often frame such cases as de facto targeting of American industry, while EU officials argue their mandate is market‑agnostic: to safeguard competition within the Single Market. Any sharp U.S. response could feed into broader negotiations over data transfers, platform regulation, and digital trade clauses, potentially complicating cooperation on issues like AI standards or cybersecurity.
Impacts on market participants
Advertisers: Could gain greater choice among demand‑side platforms, improved transparency about auction dynamics, and better pricing if remedies curb self‑preferencing.
Publishers: Might benefit from fairer access to demand and reduced take‑rates if competing exchanges and ad servers are not disadvantaged.
Rivals: Enhanced interoperability and non‑discrimination could lower barriers to entry, encouraging innovation in privacy‑preserving ad tech and measurement.
Consumers: Competition can spur better ad relevance controls, fewer tracking practices that lack consent, and more diverse ad‑funded services.
Historical context
The EU has pursued several high‑profile antitrust actions in digital markets over the past decade, frequently centered on gatekeeper conduct and leveraging across adjacent markets. Previous cases have emphasized how vertical integration and control of critical data or interfaces can allow a dominant firm to tilt outcomes in its favor, even without explicit exclusivity contracts. This new action fits that pattern by scrutinizing the mechanics of ad auctions and the incentives of a vertically integrated provider that sits on both the buy and sell sides.
Key takeaways
EU officials allege abuse of dominance in online advertising, focusing on how control of multiple ad tech layers can foreclose rivals.
Potential remedies range from behavioral commitments (data separation, non‑discrimination, interoperability) to stronger structural options if needed.
The case could intensify U.S.–EU friction over tech regulation, with broader consequences for digital trade and policy coordination.
Advertisers, publishers, and consumers may benefit from increased competition, transparency, and innovation if effective remedies are implemented.
Anthropic Agrees to Pay $1.5 Billion to Settle Lawsuit With Book Authors
Nytimes • Cade Metz • September 5, 2025
Regulation•USA•Copyright•GenerativeAI•Licensing

Overview
Anthropic has agreed to pay $1.5 billion to settle a lawsuit brought by book authors, a deal the article describes as “the largest payout in the history of U.S. copyright cases.” Beyond ending a high-profile dispute, the settlement marks a watershed moment for generative AI: it signals that large-scale model training on copyrighted books will increasingly require compensation to rights holders rather than relying on unlicensed scraping or fair use defenses. The outcome is poised to reshape how AI companies acquire data, how creators are paid, and how investors model the cost of building state-of-the-art systems.
What the settlement means
The size of the payout underscores how courts and litigants are valuing the use of long-form, high-quality text in training advanced language models. By resolving the authors’ claims with a record figure, Anthropic is effectively acknowledging that the underlying literary works carried substantial commercial value in model development. The article suggests this could become a template for the industry, nudging competitors toward negotiated licenses with authors, publishers, and collecting societies. If replicated, such deals would formalize a two-sided market in which AI developers pay for training inputs, much like music streaming platforms pay for catalogs.
Implications for creators and publishers
For authors, the settlement is a breakthrough validation that their works are not merely “inputs” but valuable intellectual property that warrants remuneration in the AI era. It could lead to broader licensing frameworks where authors and publishers receive recurring payments when their books are used to train or fine-tune models. Over time, expect more granular attribution, audit rights, and tiered pricing based on a work’s originality, sales history, or proven contribution to performance benchmarks. A successful path here may also encourage similar claims from journalists, academics, and other content creators whose archives have been ingested into training corpora.
Implications for AI companies
For AI developers, the headline cost redefines the economics of scaling. Training datasets may shift from opportunistically assembled web scrapes to curated, licensed corpora, potentially improving data quality while materially increasing cash requirements and compliance overhead. Product roadmaps will need to incorporate rights-clearance processes, content provenance tracking, and model governance that can demonstrate lawful sourcing. Firms with strong balance sheets or strategic partnerships with publishers could gain an edge, while smaller startups may favor synthetic data generation, domain-specific datasets, or alliances that pool licensing costs.
Regulatory and market ripple effects
The settlement will likely influence ongoing legislative debates about fair use, text and data mining exceptions, and collective licensing. Regulators may view the agreement as evidence that market-based solutions can function, while also considering rules to standardize opt-in/opt-out signals and transparent reporting of training sources. Internationally, jurisdictions with neighboring rights or stronger collective management traditions may accelerate toward statutory or extended collective licenses for AI training. The deal could also affect valuations, with investors discounting companies that lack clear data rights and rewarding those that secure durable licensing pipelines.
Why this is a precedent-setting moment
A record payment sets a reference point for future negotiations and settlements across creative industries.
The article’s characterization of the settlement as the “largest payout in the history of U.S. copyright cases” elevates the dispute from a single lawsuit to a sector-wide signal.
By moving money to rights holders, the deal reframes the ethics and economics of AI training, putting compensation and consent at the center of innovation narratives.
Key takeaways
$1.5 billion signals a new cost baseline for high-quality training data in generative AI.
Expect more companies to seek licenses with authors and publishers rather than rely on contested fair use interpretations.
Creators gain leverage to negotiate ongoing compensation and transparency around how their works influence AI behavior.
Compliance, provenance tracking, and data governance become strategic differentiators for AI firms.
The settlement will shape regulatory agendas and investor diligence, making lawful data sourcing a prerequisite for scaling.
Education
Unbundle the University
Yascha Mounk • September 4, 2025
Education•Universities•TuitionCosts•Ideological Diversity•Unbundling

Something has gone badly wrong with the American university.
As recently as a decade ago, a big bipartisan majority of Americans said that they have a lot of trust in higher education. Now, the number is down to about one in three.
The decline in public support for universities has many causes. It is rooted in the widespread perception that they have become ideological monoliths, barely tolerating the expression of any conservative opinions on campus. It has to do with the rapidly growing endowments of the largest universities, which now command a degree of tax-exempt wealth that seems to many people out of all proportion to their pedagogical mission. It has to do with their admissions policies, which judge prospective students on the color of their skin and the degree of their disadvantage, seemingly in defiance of a recent Supreme Court order. And it has to do with the rapidly rising costs of university, with the annual price of attendance now approaching six figures at many selective schools.
The decline in public support for higher education has also had severe consequences. Donald Trump and his allies have clearly identified universities as a significant bastion of left-wing political power, and seem determined to weaken them by any means possible. The resulting assault on top institutions from Columbia to Harvard is deeply illiberal. Whatever the faults of the universities, it obviously chills speech and undermines academic freedom when the federal government tries to exact revenge by doing what it can to weaken the sector. But what’s striking about the Trump administration’s attack on American higher education is not just how brutal and illiberal it is; it’s also how little most Americans seem to care.
Anybody who wants American universities to thrive—as I do—therefore needs to walk and chew gum at the same time. Institutions like Harvard are right to resist attempts to erode their academic freedom by imposing the substantive views of the Trump administration on them. It is therefore good news that a district court judge ruled yesterday that the manner in which the administration canceled federal funding for Harvard violated the university’s First Amendment rights. But rightful resistance to an illiberal president must not serve as an excuse to keep ignoring the genuine problems which have led to such deep popular revulsion for the entire sector.
CEO Sundar Pichai's remarks at the White House AI Education Taskforce
Blog • Sundar Pichai • September 4, 2025
Education•Schools•AI•Gemini•Grants
Today Google CEO Sundar Pichai highlighted efforts to help American high schoolers succeed in the AI era, including our recent $1 billion commitment to support education and job training programs in the U.S., and offering Gemini for Education to every high school in America.
Editor’s note: Today Sundar Pichai spoke at the White House Panel on AI Education event in Washington, where he highlighted our efforts to support AI education, including offering Gemini for Education to every high school in America. Below is an edited transcript of his remarks.
Mrs. Trump, Director Kratsios, esteemed Cabinet officials, hello.
It’s an honor for me to be here and to support the First Lady’s Presidential AI Challenge. Through this initiative, you are inspiring young people to use technology in extraordinary ways.
This is deeply important to me. Having regular access to computers changed my life, and led me on the path to Google.
I was drawn to its mission: to organize the world's information and make it universally accessible and useful. Today we see AI as the most profound way we will deliver on that mission — and transform knowledge and learning.
We can imagine a future where every student, regardless of their background or location, can learn anything in the world — in the way that works best for them.
We’ve been focused on this for decades. It’s why we built Chromebooks for every classroom, and why we’ve worked to make our AI model, Gemini, the world’s leading model for learning.
It’s also why we’re offering Gemini for Education to every high school in America. That means every high school student and every teacher has access to our best AI tools, including Guided Learning — tools that could be helpful for students taking the AI Challenge.
We also recently committed $1 billion over the next three years to support education and job training programs in the U.S. And today, I’m excited to share that $150 million of that $1 billion will go towards grants to support AI education and digital wellbeing.
A reminder for new readers. Each week, That Was The Week, includes a collection of selected essays on critical issues in tech, startups, and venture capital.
I choose the articles based on their interest to me. The selections often include viewpoints I can't entirely agree with. I include them if they make me think or add to my knowledge. Click on the headline, the contents section link, or the ‘Read More’ link at the bottom of each piece to go to the original.
I express my point of view in the editorial and the weekly video.

